
索引页链接补全机制的一种方法
一、背景
Spider位于搜索引擎数据流的最上游,负责将互联网上的资源采集到本地,提供给后续检索使用,是搜索引擎的最主要数据来源之一。spider系统的目标就是发现并抓取互联网中一切有价值的网页,为达到这个目标,首先就是发现有价值网页的链接,当前spider有多种链接发现机制来尽量快而全的发现资源链接,本文主要描述其中一种针对特定索引页的链接补全机制,并给出对这种特定类型的索引页面的建议处理规范用于优化收录效果。
当前大多数互联网网站以索引页和翻页的形式来组织网站资源,当有新资源增加时,老资源往后推移到翻页系列中。
如下图所示:
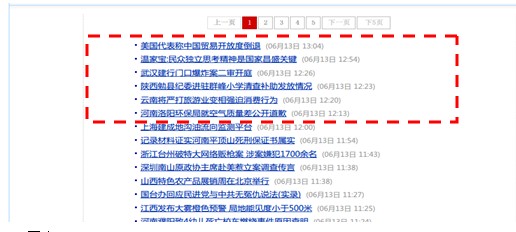
http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml
图2为18小时后该网页翻页系列的第四页的内容,在这段时间内新增了三页多的资源,图1中红色矩阵圈到的资源在18个小时后已经往后有序推移到第4页的红色方块处。

http://roll.news.sina.com.cn/news/gnxw/gdxw1/index.shtml
对spider来说,这种特定类型的索引页是资源链接发现的一种有效渠道,但是由于spider是定期检查这些网页来获得新增的资源链接,检查的周期同资源链接发布的周期不可避免会有不同(spider会尽量探测网页的发布周期,以合理的频率来检查网页),周期不同的时候,资源链接很有可能就被推到翻页序列中,所以spider需要对这种特殊类型的翻页系列作翻页补全,从而保证收录资源的完全。
二、主要思路
本文主要讨论这种资源按发布时间有序排布的网页,即新发布的资源排布在翻页第1页(或翻页最后一页),老的资源往后(或者往前)有序推移的索引页的补全机制。主要思路是将整个翻页系列的网页看成一个整体,综合判定它们的抓取状态,通过记录每次抓取网页发现的资源链接,然后将此次发现的资源链接与历史上发现的资源链接作比较,如果有交集,说明该次抓取发现了所有的新增资源;否则,说明该次抓取并未发现所有的新增资源,需要继续抓取下一页甚至下几页来发现所有的新增资源。
2.1 资源链接是否按照时间排序
判断资源是否按发布时间排布是这类页面的一个必要条件,那么如何判断资源是否按发布时间排布呢?如上面图1所示,有些页面中每个资源链接后面跟随着对应的发布时间,通过资源链接对应的时间集合,判断时间集合是否按大到小或小到大排序,如果是的话,则说明网页中的资源是按发布时间有序排布,反之亦然。图1中资源从上到下对应的时间是越来越小的,即是资源按发布时间有序的。
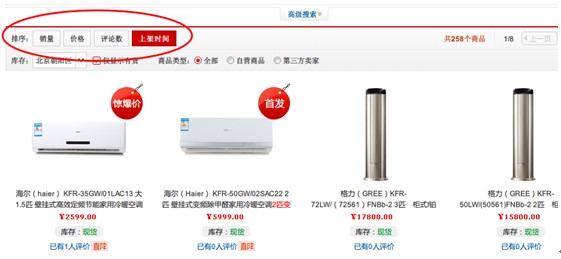
还有一类网页,如下面图3所示,网页内容中有多种排序方式,如按销量排序,按价格排序,如评论数排序,按上架时间排序。通过识别和提取当前的排序方式,然后判断当前的排序方式是否为按时间排序,如果是,则说明网页中的资源是按发布时间有序排布,反之亦然。图3中的排序方式是按上架时间排序,属于时间排序方式,所以该网页发布的资源是按发布时间有序的。
另外也会根据资源链接抓回后提取的发布时间综合判断。
2.2 补全机制
对于按发布时间有序排布在索引页系列的资源链接,如何保证新发布的资源都被收录呢?如上述所说,在18个小时后,图1中的资源链接已经往后有序推移到翻页第4页了,如此看,这段时间内新增了翻页第2,3,4页索引的资源链接,那么,spider就需要完全的收录这些新增的资源;
首先,当spider抓取18小时后的第1页时,将新发现的资源链接集合,与上一次18小时前第1页索引页调度记录的资源链接集合作比较,会发现两次调度发现的资源链接没有交集,所以就可能存在漏链。进而需要继续发起第2页的调度,第2页发现的资源链接集合与之仍然没有交集,所以还可能存在漏链,继续发起第3页,第4页的调度,最终如图2所示,红框中的链接与上一次索引页调度记录的资源链接有交集,因此可以断定已经补全了这段时间内新增的资源,从而结束翻页系列的调度,并保证了该翻页系列的所有链接的补全,从而提升搜索产品的收录效果。
2.3 翻页条的识别和翻页条对应的链接序列区块的识别
为了达到上面的效果,除了需要识别翻页系列的排序方式是不是按照时间排序,还需要识别索引页中的翻页条和其对应的链接区块。
因为没有翻页条的识别,spider系统就不可能把这个翻页序列的所有链接绑定起来,整体考虑它们的状态,那么调度抓取的结果就是随机的,从而不能保证补全效果,当前通过网页中的翻页的一系列特征,通过机器学习的方法来识别网页中的翻页区块和翻页深度,以及上一页,下一页的链接,从而为上述补全机制提供基本数据。
另外一方面,即使有了翻页条的识别,没有对应链接区块的识别,上述补全机制还是不能工作,因为上述机制需要对比发现的链接的集合来判定终止条件,所以,也需要识别翻页条对应的链接区块,从而提供翻页终止条件。
特殊情况下,一个网页可能包含多个翻页条,这种情况更需要进行翻页条和链接区块的对应。
三、建议的方法和标准
当前百度spider系统对网页的类型,网页中翻页条的位置,翻页条对应的索引列表,以及列表是否按照时间排序都会做相应的判断,并根据实际的情况进行处理,但是机器自动的判断方法毕竟不能做到100%的识别准确率,所以如果站长能够通过在页面中添加一些百度推荐的标签来标志相应的功能区域,就可以极大地提高我们识别的准确率,从而提高spider系统对网站资源发现的即时性,从而提高网站的收录效果。
Spider链接补全当前最关心的是网页的翻页条和翻页条对应的索引链接列表的区块,所以可以通过区块的元素(譬如div,ul)的class属性来标志相应的特征,供百度spider识别使用,建议使用下面的属性来标志:
表1 支持的CLASS扩展属性
譬如百度新闻的页面可以这样设置:

对翻页条对应的区块元素p可以设置class属性Baidu_paging_indicator,对该翻页条对应的主体链接的区块元素div,设置 Baidu_paging_content_indicator Orderby_posttime,这样翻页条和对应的链接区块就对应起来,并且告知了百度是按照发布时间排序的,从而可以优化spider系统的抓取行 为,改善站点的收录效果。
四、总结
除了上面说明的链接发现方法,Baidu的抓取系统还有非常多的其他手段来保证对 有价值网站的收录覆盖率,上述方法只是针对特定索引页类型而采取的一种特定的手段,互联网站长可以参考使用。站长也可以通过spider的站长平台来了解 如何获得更快更好的网站收录效果,譬如直接通过sitemap协议推送链接。站长平台地址:http://zhanzhang.baidu.com/,刚刚改版,全新功能呈现。
文章来源:百度搜索研发部
-

广告合作
-

QQ群号:707632017


















