

类型:人工智能
简介:一款基于深度学习和自然语言处理技术的产品,人气赶超ChatGPT。
本篇教程将手把手教你在个人设备上部署深度求索(DeepSeek)大语言模型。本方案已在Windows 11 22H2、Ubuntu 20.04 LTS环境下通过验证。通过灵活选择模型版本,用户可在消费级硬件上实现类GPT-3.5的对话体验,特别适合需要数据隐私保护的本地化AI应用场景。
一、DeepSeek环境准备
1、下载跨平台推理框架
访问Ollama官网(https://ollama.com/download)获取最新安装包,支持Windows/macOS/Linux三大平台。建议选择稳定版(Stable Release)确保兼容性。
2、搜索deepseek选择第一项即可

二、DeepSeek模型大小与显卡需求
| 模型版本 | 参数量 | 最低显存 | 推荐硬件 | 适用场景 |
|---|---|---|---|---|
| DeepSeek-R1 | 70B | 40GB | RTX A6000 | 科研级推理 |
| Distill-32B | 32B | 24GB | RTX 3090 | 复杂任务处理 |
| Distill-14B | 14B | 16GB | RTX 4080 | 多轮对话系统 |
| Distill-7B | 7B | 10GB | RTX 3080 | 本地开发调试 |
| Lite-1.5B | 1.5B | 8GB | RTX 3060 | 入门级体验 |
注:NVIDIA显卡需安装515.65+版本驱动,建议使用CUDA 11.7以上环境
三、DeepSeek核心部署流程
1、拉取模型镜像
ollama pull deepseek-r1:1.5b

下载进度实时显示,1.5B模型约需5分钟(百兆宽带),等待安装即可。
2、启动推理服务
ollama run deepseek-r1:1.5b
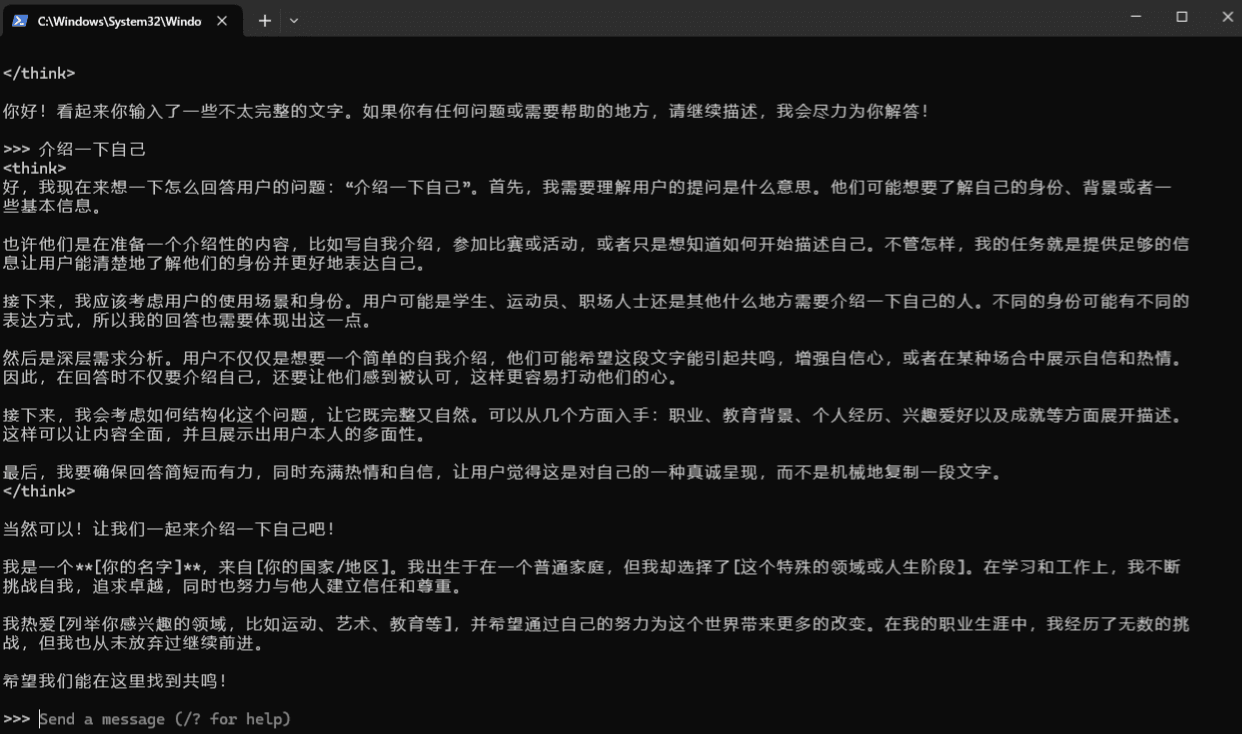
成功启动后终端显示交互提示符 >>>
3、功能验证测试
输入测试指令:
>>> 请用Python实现快速排序算法,并说明时间复杂度,观察是否返回正确的代码实现及复杂度分析。
四、运维管理指令集
# 查看已部署模型 ollama list # 终止当前会话 /bye # 更新指定模型 ollama pull deepseek-r1:1.5b --update # 删除冗余模型 ollama rm deepseek-r1:1.5b
五、可视化控制台搭建(Chatbox方案)
1、客户端安装
访问https://chatboxai.app/zh下载跨平台客户端,推荐v2.9.0+版本

2、网络配置关键步骤
新建系统变量:
OLLAMA_HOST=0.0.0.0 OLLAMA_ORIGINS=*
开放11434端口(Windows Defender需添加入站规则)

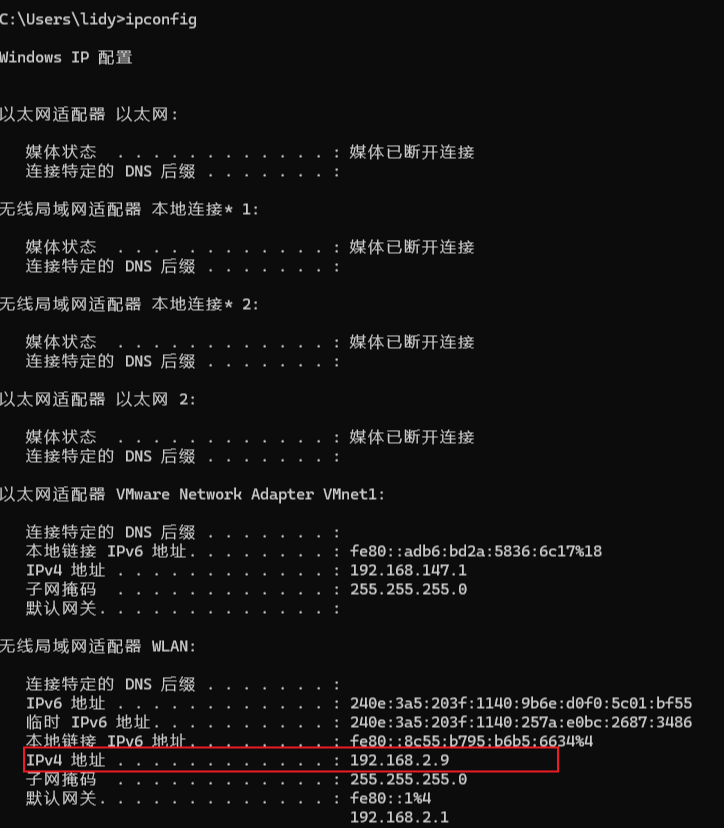
多设备连接配置
获取本机内网IP(cmd执行ipconfig),在Chatbox设置: API端点 → http://[你的IP]:11434


六、安全强化建议
1、内网隔离部署
建议在独立VLAN或通过防火墙策略限制访问源IP。
2、API防护方案
# 启动带认证的服务 ollama serve --auth [username]:[password] 对应Chatbox需在API URL添加认证信息: http://user:pass@ip:11434
3、传输加密配置(可选)
通过Nginx反向代理配置SSL证书,实现HTTPS加密通信。
七、性能调优技巧
1、量化加速方案
ollama run deepseek-r1:1.5b --quantize q4_0
通过4bit量化可提升30%推理速度,精度损失<2%
2、批处理优化
设置环境变量:
export OLLAMA_NUM_PARALLEL=4
根据CPU核心数调整并行度(建议为核心数×2)
3、显存优化模式
ollama run deepseek-r1:1.5b --low-vram
启用分层加载策略,适合显存紧张环境
八、常见问题诊断
Q: 出现CUDA out of memory错误
A: 尝试–low-vram模式或选用更小模型
Q: 响应速度过慢
A: 检查是否启用GPU加速(nvidia-smi查看显存占用)
Q: API连接超时
A: 确认防火墙设置,Windows需允许Ollama通过专用网络
部署完成后,建议运行基准测试:
ollama bench deepseek-r1:1.5b
正常输出应显示Tokens/s >20(GPU模式)














