

类型:人工智能
简介:基于AI的绘画生成工具,主要用于根据文本描述生成详细图像。
本教程将详细解析如何搭建Stable Diffusion模型训练环境,并指导完成模型训练的各个环节。帮助大家掌握从零开始训练Stable Diffusion模型的完整流程,帮助在实践中解决训练中可能遇到的问题并提高生成效果。
一、Stable Diffusion环境搭建
本教程以 GitHub 上的 bmaltais/kohya_ss 为例。该项目为 Windows 系统提供了一个 GUI 训练面板。如果打算进行训练,请确保设备已经安装了 Python 3.10.6 和 Git。
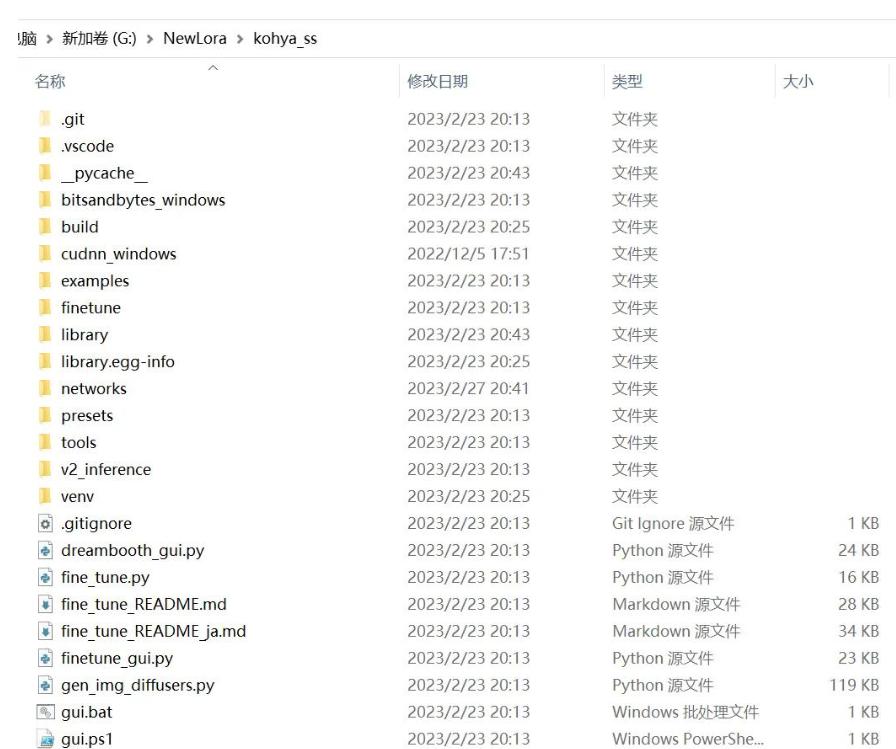
启动 Powershell(管理员模式),执行以下命令以解除执行策略限制:
Set-ExecutionPolicy Unrestricted
然后选择“是”,关闭该窗口。
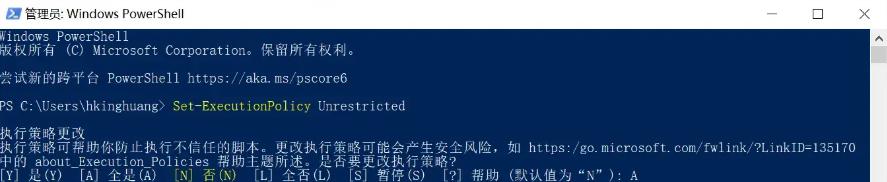
1、启动普通 Powershell 窗口,在需要克隆仓库的路径下,执行以下命令:
执行 accelerate config 命令时,会出现一些设置选项,依次选择: git clone https://github.com/bmaltais/kohya_ss.git cd kohya_ss python -m venv venv .\venv\Scripts\activate pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116 pip install --use-pep517 --upgrade -r requirements.txt pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion- webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\ cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site- packages\bitsandbytes\cextension.py cp .\bitsandbytes_windows\main.py .\venv\Lib\site- packages\bitsandbytes\cuda_setup\main.py accelerate config
在执行“accelerate config”后,它将询问一些设置选项。请按照以下选项依次选择:
This machine No distributed training NO NO NO all fp16
30 系、40 系显卡可选择安装 CUDNN:
.\venv\Scripts\activate python .\tools\cudann_1.8_install.py
二、Stable Diffusion环境更新
若需更新项目仓库,可以执行以下命令:
git pull .\venv\Scripts\activate pip install --use-pep517 --upgrade -r requirements.txt
启动训练界面时,可以在 Powershell 中执行命令,或者直接双击 gui.bat 文件。当界面弹出后,直接访问指定的 URL 即可。

三、Stable Diffusion训练流程
1、欠拟合:模型未从数据集中学习到有效信息,生成的结果变化大且不一致。
2、效果良好:模型能对训练集和非训练集中的数据都做出较为准确的预测,具有较好的泛化能力。
3、过拟合:模型对训练集有非常高的精确度,但对非训练集的预测差异大,失去泛化能力。
(一)准备训练集
训练集的图片应尽量高清,风格统一但内容形式多样(例如动作、服装、场景等)。样本数量的多少会直接影响训练效果:
- 样本量过少:模型可能会出现欠拟合,即无法有效学习;
- 样本量过大:模型可能会出现过拟合,即只能应对训练集中的数据,无法处理新的或不同的数据。
(二)图片裁剪
在训练过程中,所有图片应裁剪为相同的尺寸。可以在 SD webui 界面自动裁剪图片,也可以手动裁剪。常见的尺寸为 512×512 像素。虽然较大尺寸的图片会占用更多显存,但也能捕捉到更多的细节。
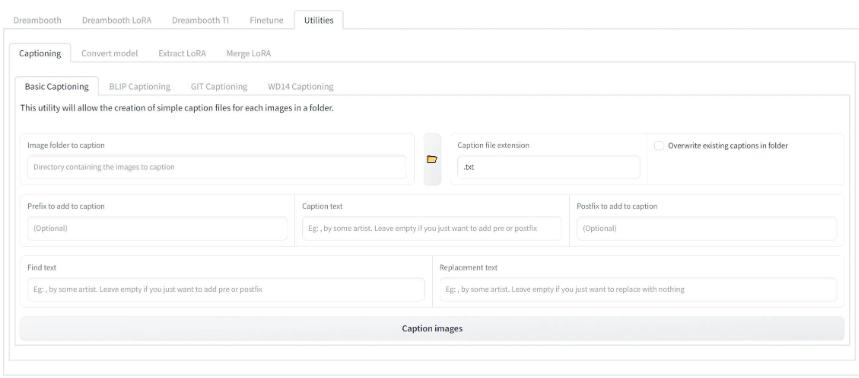
(三)图片打标
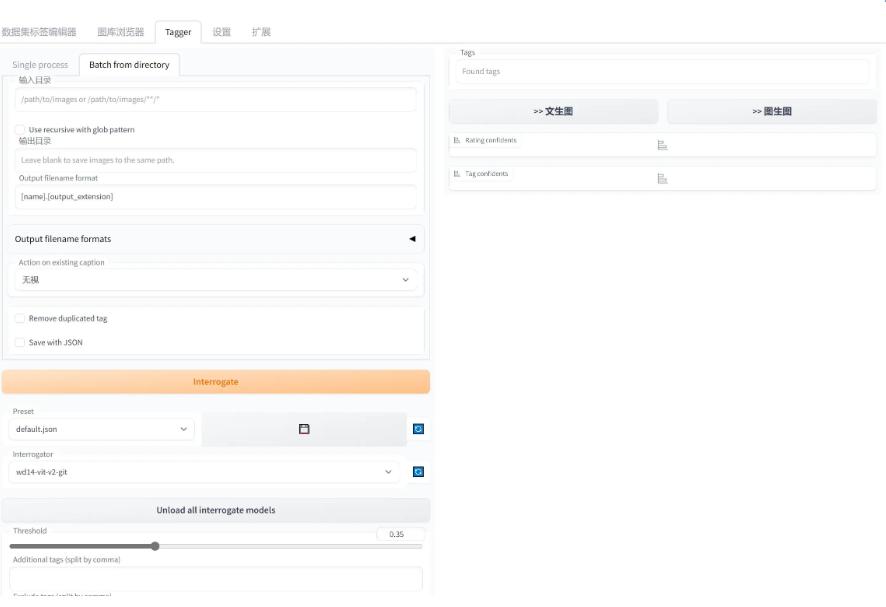
生成关键词:在训练环境或 SD webui 页面上为每张图片打标签。不同打标器可能生成不同的描述效果,可以对比不同打标器的效果。例如:
本义描述:一个铁匠在打铁。

使用不同打标器的效果:
- BLIP:一个男人在厨房里,壁炉里生着火,手里拿着锤子,另一只手也拿着锤子;
- deepbooru:一个男孩,黑色手套,手套,室内,男人特写,衬衫,短袖,单人;
- Tagger(WD14):一个男孩,烹饪,煎锅,男人特写,单人,手套,围裙,火,棕色鞋,黑色手套,靴子,炉子,厨房,握着,胡子,头巾,蓝色衬衫,衬衫;
- BLIP Captioning:一个男人正在加工一块金属;
- GIT Captioning:一幅画,画的是一个手上戴着手套、拿着锤子的铁匠;
- 原始关键词:1boy, cooking, frying pan, male focus, solo, gloves, apron, fire, brown footwear, black gloves, boots, stove, kitchen, holding, facial hair, bandana, blue shirt, shirt
- 合并后关键词:Smith, cooking, frying pan, male focus, solo, gloves, apron, fire, brown footwear, black gloves, boots, stove, kitchen, holding, bandana, blue shirt, shirt
- 关键词合并:将与训练目标最相关的关键词进行合并,以简化描述。例如,若训练目标为一个有大胡子的男性,可以将“1boy, facial hair”合并为“Smith”。通过将相似或重复的描述归为一个关键词,避免过度冗余,使模型能够更加专注于关键特征。
示例:
- 合并前:1boy, cooking, frying pan, male focus, solo, gloves, apron, fire, brown footwear, black gloves, boots, stove, kitchen, holding, facial hair, bandana, blue shirt, shirt
- 合并后:Smith, cooking, frying pan, male focus, solo, gloves, apron, fire, brown footwear, black gloves, boots, stove, kitchen, holding, bandana, blue shirt, shirt
- 编组:相同主题的图片可以通过关键词进行分组。例如训练目标是“Smith”,可以为 Smith 制作全图、背景图、前景图等,并根据不同的需求对其进行处理。

(四)正则化
每张训练图片通常由“训练目标”和“其他要素”两部分组成。以 Smith 为例,训练集中的“铁匠铺、打铁、铁匠”等是模型的先验知识,可以让模型不需要重新学习这些部分,从而提高训练效率并提高泛化能力。正则化的目的是通过减少模型复杂度来增强其泛化能力。过于复杂的模型需要更多的样本来避免过拟合。
正则化标签应与训练集中的类别一致,确保图片数量相匹配。需要注意的是,正则化并非必须操作,可以根据训练集的特点和目标来决定是否使用正则化。
(五)文件路径组织
在开始训练之前,确保文件路径组织符合规范。例如,若训练目标是一个名为 Smith 的女孩,且分为 sls 和 cpc 两个子类别,则路径结构应为:
train_girls ----○10_sls 1girl ----○10_cpc 1girl reg_girls ----○1_1girl
其中:
- train_girls 目录下保存训练集,命名规则为“训练次数_<标识符> <类别>”,例如“10_sls 1girl”表示名为 sls 的女孩的训练集将训练 10 次;
- reg_girls 目录下保存正则化集,命名规则为“训练次数_<类别>”,例如“1_1girl”表示该目录下的图片只包含一个女孩,不会重复使用。















