
MySQL作为一种广泛使用的关系数据库管理系统,能够处理大量的数据查询,但在高负载或复杂查询的情况下,可能会导致慢查询问题。慢查询不仅增加了数据库的响应时间,还可能影响到应用程序的整体性能。本文将详细介绍如何识别慢查询、分析其原因并提供具体的优化建议,以帮助提升数据库性能和查询效率。
一、定位慢查询MySQL
1、确认是否开启慢查询日志
通过以下命令检查慢查询日志的状态:
SHOW VARIABLES LIKE "%slow%";
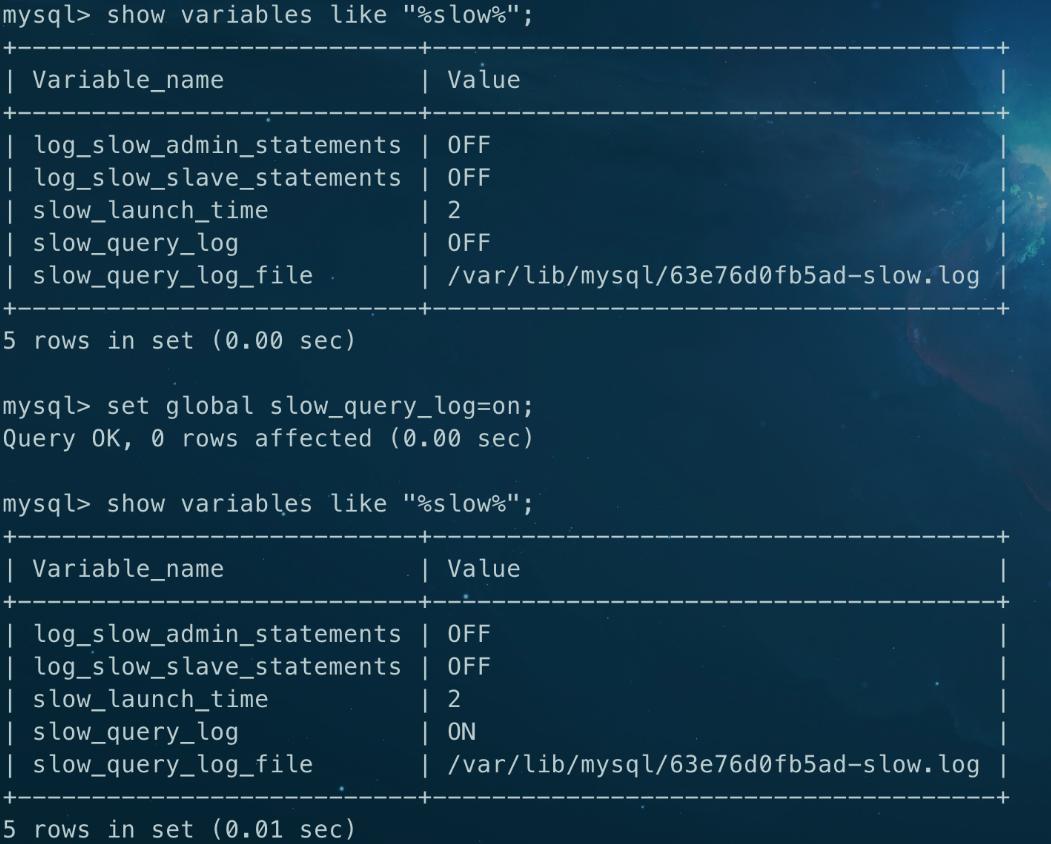
如果 “slow_query_log” 为 “OFF”,表示未开启慢查询日志。可以使用以下命令开启:
SET GLOBAL slow_query_log = ON;
注意:上述设置仅在当前会话中生效。若需永久生效,请在 “my.cnf” 配置文件中添加以下内容:
ini [mysqld] slow_query_log = ON slow_query_log_file = /path/to/your/slow-query.log
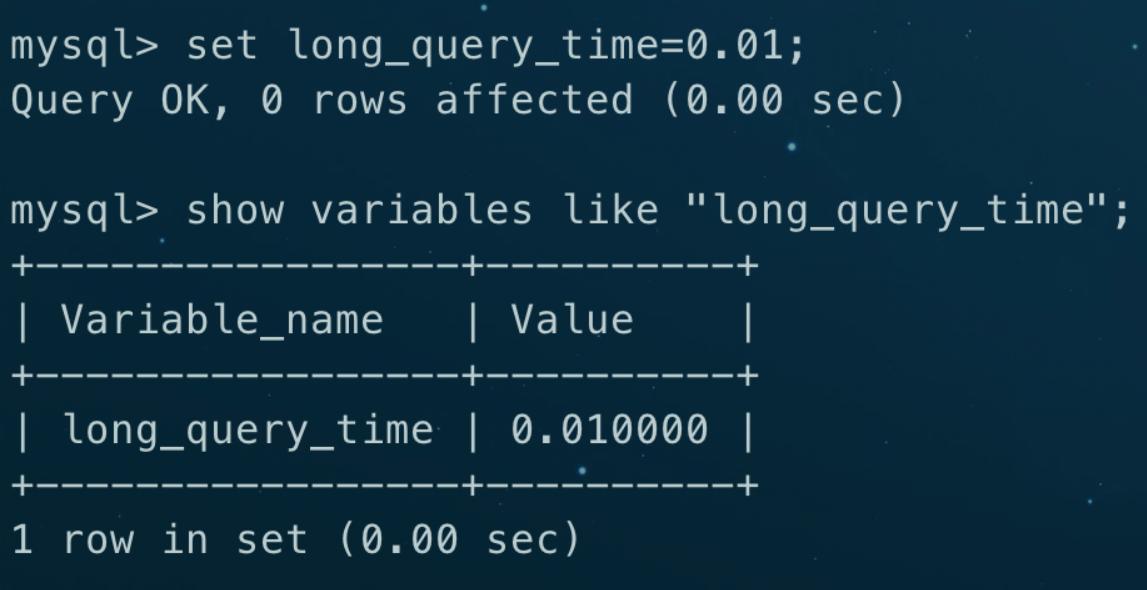
2、设置时间限制
使用以下命令查看当前的慢查询时间限制:
SHOW VARIABLES LIKE "long_query_time";
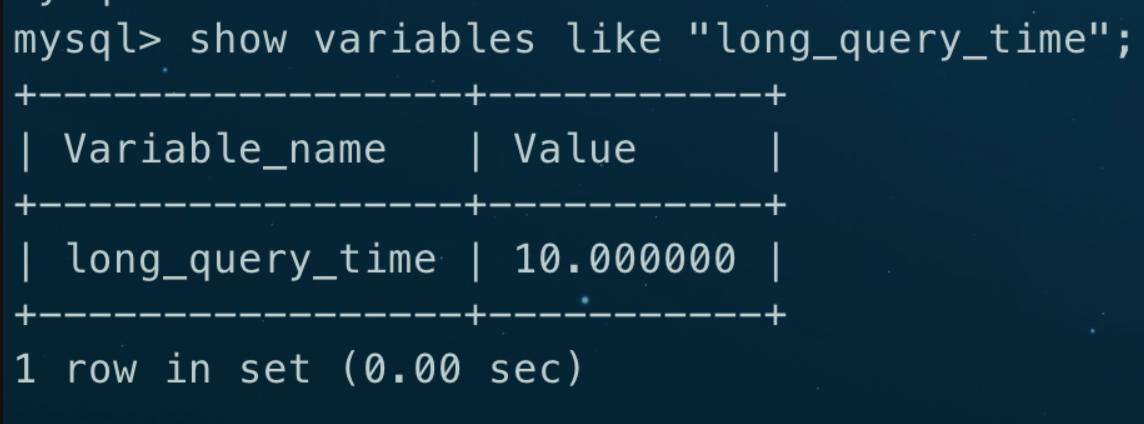
此值表示执行时间超过该值的查询将被记录为慢查询。可以根据需要适当调整此值,测试时可以设置得较小一些。
3、定位具体的慢查询
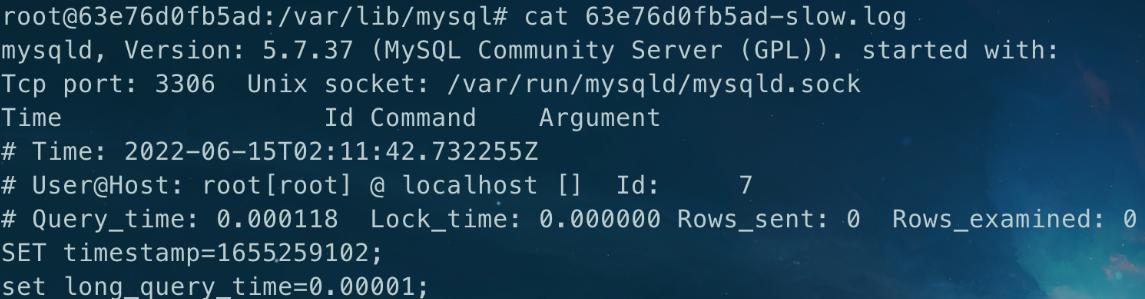
慢查询日志中将记录以下信息:
- Time:日志记录的时间;
- User@Host:执行的用户及其主机;
- Query_time:查询耗时;
- Lock_time:数据库锁定时间;
- Rows_sent:发送给请求方的记录条数;
- Rows_examined:扫描的记录条数;
- SET timestamp:语句执行的时间点。
注意:如果 MySQL 运行在 Docker 环境中,需要进入到 MySQL 容器内部才能查看慢查询日志。
4、相关MySQL查询
可以使用以下命令查询 MySQL 的操作信息:
- SHOW STATUS LIKE “com_insert%”; — 获得插入次数
- SHOW STATUS LIKE “com_delete%”;– 获得删除次数
- SHOW STATUS LIKE “com_select%”;– 获得查询次数
- SHOW STATUS LIKE “uptime”; — 获得服务器运行时间
- SHOW STATUS LIKE ‘connections’;– 获得连接次数
5、分析慢查询使用EXPLAIN

使用 “EXPLAIN” 分析具体的 SQL 查询,了解查询执行计划:
EXPLAIN SELECT * FROM your_table WHERE your_condition;
输出字段及说明:
- id:选择标识符;
- select_type:表示查询的类型;
- table:输出结果集的表;
- partitions:匹配的分区;
- type:表的连接类型;
- possible_keys:可能使用的索引;
- key:实际使用的索引;
- key_len:索引字段的长度;
- ref:列与索引的比较;
- rows:估算的扫描行数;
- filtered:按表条件过滤的行百分比;
- Extra:执行情况的描述。
6、EXPLAIN字段说明
type 字段说明:
- “system”:表中仅有一条数据,等于系统表;
- “const”:使用主键或唯一索引,查询变量被转为常量;
- “eq_ref”:使用唯一索引,返回匹配的唯一数据;
- “ref”:使用非唯一索引,返回多行匹配的数据;
- “range”:范围查询,利用索引返回范围内的行;
- “index”:以索引顺序全表扫描;
- “all”:全表扫描,应尽量避免。
extra 字段说明:
- “using index”:使用了覆盖索引,可以直接返回所需数据;
- “using index condition”:索引下推,减少回表次数;
- “using where”:未使用索引,通过 WHERE 过滤获取数据;
- “using temporary”:使用临时表保存结果,效率较低;
- “using filesort”:使用文件排序,效率较低,尽量避免。
二、慢MySQL优化建议
1、避免使用子查询
SELECT * FROM t1 WHERE id (SELECT id FROM t2 WHERE name='hechunyang'); (优化只针对SELECT有效,对UPDATE/DELETE子 查询无效)
2、读取适当的记录LIMIT M,N
可以改为:
SELECT * FROM t WHERE 1 LIMIT 10;
3、分组统计可以禁止排序
SELECT goods_id,count(*) FROM t GROUP BY goods_id;
默认情况下,MySQL对所有GROUP BY col1,col2…的字段进⾏排序。如果查询包括GROUP BY,想要避免排序结果的消耗,则可以指定ORDER BY NULL禁止排序。
可以改为:
SELECT goods_id,count(*) FROM t GROUP BY goods_id ORDER BY NULL;
4、禁止不必要的ORDER BY排序
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id WHERE 1 = 1 ORDER BY u.create_time DESC;
可以改为:
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id;
5、尽量不要超过三个表join
需要join的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。
6、在varchar字段上建立索引时,必须指定索引长度
没必要对全字段建立索引,根据实际文本区分度决定索引长度。索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
7、不要使用 select
只返回需要的字段。
8、排序请尽量使用升序
9、尽量使用数字型字段
若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
10、避免索引失效
1)字段类型转换导致不用索引
如字符串类型的不用引号,数字类型的用引号等,这有可能会用不到索引导致全表扫描;
2)根据联合索引的第二个及以后的字段单独查询用不到索引。
3)字段前面不能加函数/加减运算,否则会导致索引失效。
如下面语句将进行全表扫描:
select id from t where num/2=100 SELECT * FROM t WHERE YEAR(d) >= 2016
可以改为:
select id from t where num=100*2 SELECT * FROM t WHERE d >= '2016-01-01';
4)搜索严禁左模糊或者全模糊。
select name from t where name like %s select name from t where name like %s%
5)避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
select id from t where num != 2
可以改为:
select id from t where num > 2 and num < 2
6)避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
select id from t where num is null
可以改为:设置num的默认值为0,确保没有null值。
select id from t where num=0
7)用IN或UNION来替换OR低效查询。
SELECT * FROM t WHERE LOC_ID = 10 OR LOC_ID = 20 OR LOC_ID = 30;
可以改为:
SELECT * FROM t WHERE LOC_IN IN (10,20,30);
或:
SELECT FROM t WHERE LOC_IN = 10 UNION ALL SELECT FROM t WHERE LOC_IN = 20 UNION ALL SELECT * FROM t WHERE LOC_IN = 30
对于连续的数值,能用 between 就不要用 in 了。
select id from t where num between 1 and 3
8)在 where 子句中使用参数,也会导致全表扫描。
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
9)删除表所有记录请用 truncate,不要用 delete。
10)存储过程和触发器设置。
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
-

广告合作
-

QQ群号:707632017



















