
Milvus是一款专为AI应用和向量相似度搜索而设计的开源向量数据库。本文将主要介绍Milvus的核心功能、工作原理、关键概念、使用场景、支持的索引与度量方式、典型应用案例、系统架构以及相关工具。
一、什么是Milvus向量数据库?
Milvus诞生于2019年,其核心目标在于存储、索引及管理由深度学习网络及其他机器学习模型生成的海量嵌入向量数据。作为一款专门处理向量查询的数据库,Milvus能够在大规模数据集上有效索引向量。与传统的关系型数据库主要处理预定义模式的结构化数据不同,Milvus从底层设计上就是为了管理和处理由非结构化数据转换来的嵌入向量。
随着互联网的发展,非结构化数据(如电子邮件、社交媒体帖子、物联网数据等)变得越来越普遍。为了方便计算机理解和处理这些数据,通常需要将其转换为向量形式。Milvus正是为存储和索引这些向量数据而设计,它通过计算向量间的相似度来分析它们的关系:向量越相似,代表原始数据源也越相似。
Milvus向量数据库工作流程如下图:
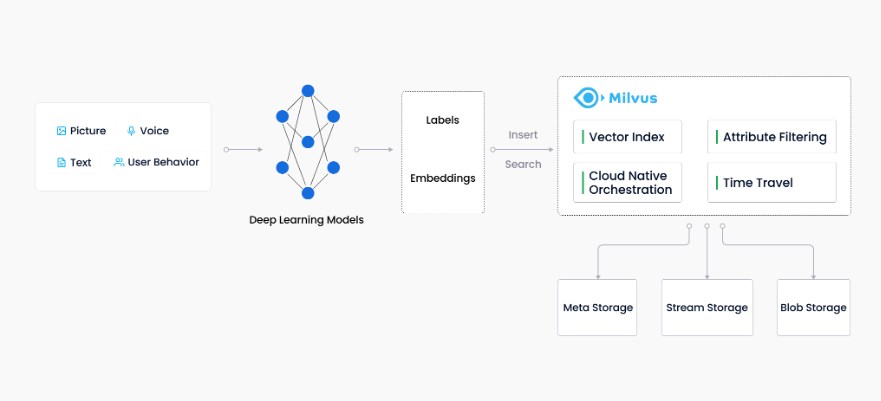
二、Milvus关键概念
如果是向量数据库和相似性搜索领域的新手,以下关键概念将帮助更好地理解:
1、非结构化数据
未遵循固定模型或组织方式的信息,如图像、视频、音频和自然语言等,占全球数据的大部分。通过各种AI和ML模型,这类数据可被转换为嵌入向量。
2、嵌入向量
非结构化数据的特征提取表示,数学上表现为浮点数或二进制数组。现代嵌入技术能够将非结构化数据转化为嵌入向量。
3、向量相似性搜索
将向量与数据库中的其他向量比较,以找出最接近查询向量的向量的过程。近似最近邻(ANN)搜索算法用于加速此过程。
三、Milvus优势
- 在大规模数据集上进行向量搜索时展现高性能;
- 拥有以开发人员为中心,支持多语言和工具链的社区;
- 即使面临中断,也能保证云扩展性和高可靠性;
- 通过结合标量过滤与向量相似性搜索实现混合搜索。
四、Milvus索引和度量方式
1、索引类型
Milvus支持的大多数向量索引类型使用近似最近邻搜索(ANNS),包括:
- FLAT:FLAT 最适合于在小型百万级数据集上寻求完全准确和精确的搜索结果的场景;
- IVF_FLAT:IVF_FLAT 是基于量化的索引,最适合于在准确性和查询速度之间寻求理想平衡的场景。还有一个 GPU 版本 GPU_IVF_FLAT;
- IVF_SQ8:IVF_SQ8 是一种基于量化的索引,最适合于在磁盘、CPU 和 GPU 内存消耗非常有限的场景;
- IVF_PQ:IVF_PQ 是一种基于量化的索引,最适合于在牺牲准确性的情况下追求高查询速度的场景。还有一个 GPU 版本 GPU_IVF_PQ;
- HNSW:HNSW 是一种基于图的索引,最适合于对搜索效率有很高要求的场景。
2、相似性度量
在 Milvus 中,相似性度量用于衡量向量之间的相似性。选择一个好的距离度量有助于显著提高分类和聚类性能。根据输入数据的形式,选择特定的相似性度量以实现最佳性能。
浮点嵌入中广泛使用的度量包括:
- 欧氏距离(L2):该度量通常在计算机视觉(CV)领域中使用;
- 内积(IP):该度量通常在自然语言处理(NLP)领域中使用。
二进制嵌入中广泛使用的度量包括:
- 汉明距离(Hamming):该度量通常在自然语言处理(NLP)领域中使用;
- 杰卡德相似系数(Jaccard):该度量通常在分子相似性搜索领域中使用。
五、示例应用程序
- 图像相似性搜索:使图像可搜索,并立即从庞大的数据库中返回最相似的图像;
- 视频相似性搜索:通过将关键帧转换为向量,然后将结果输入到 Milvus 中,可以在几十亿个视频中进行搜索和推荐;
- 音频相似性搜索:快速查询大量音频数据,如语音、音乐、音效和表面相似声音;
- 推荐系统:根据用户行为和需求推荐信息或产品;
- 问答系统:自动回答用户问题的交互式数字 QA 聊天机器人;
- DNA 序列分类:通过比较相似的 DNA 序列,在毫秒级别准确地对基因进行分类;
- 文本搜索引擎:通过将关键字与文本数据库进行比较,帮助用户找到他们正在寻找的信息。
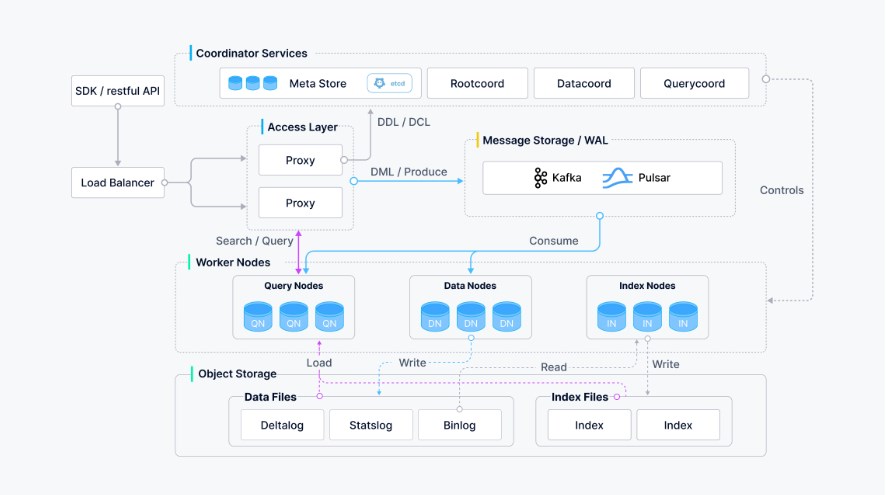
六、Milvus系统架构
作为一个云原生的向量数据库,Milvus 在设计上将存储和计算分离。为了增强弹性和灵活性,Milvus 中的所有组件都是无状态的。
系统分为四个层次:
- 接入层:接入层由一组无状态代理组成,作为系统的前端层和用户的终端点;
- 协调服务:协调服务将任务分配给工作节点,并作为系统的大脑;
- 工作节点:工作节点充当手脚,是彻底的执行者,遵循协调服务的指示并执行用户触发的 DML/DDL 命令;
- 存储:存储是系统的骨架,负责数据持久性。它包括元数据存储、日志代理和对象存储。
七、Milvus开发工具
Milvus得到了丰富的API和工具的支持,以促进DevOps。
1、API接入
Milvus 拥有在 Milvus API 之上封装的客户端库,可以从应用程序代码中以编程方式插入、删除和查询数据:
- PyMilvus
- Node.js SDK
- Go SDK
- Java SDK
我们正在努力支持更多的新客户端库。如果你想贡献,请访问 Milvus 项目(opens in a new tab) 的相应仓库。
2、Milvus生态系统工具
Milvus 生态系统提供了有用的工具,包括:
- Milvus CLI;
- Attu(opens in a new tab),Milvus 的图形管理系统;
- MilvusDM(Milvus 数据迁移),一个专门为 Milvus 设计的数据导入导出的开源工具;
- Milvus sizing(opens in a new tab) 工具,用于估算不同索引类型所需的指定向量数量的原始文件大小、内存大小和稳定磁盘大小。
八、Milvus与传统关系型数据库区别
与传统关系型数据库主要处理结构化数据不同,Milvus从底层设计就针对非结构化数据转换而来的嵌入向量进行处理,适应了互联网时代非结构化数据的爆炸性增长,例如短视频、种草图文、物联网传感器数据、蛋白质结构等等。















