
据AIGC开放社区报道,谷歌最近推出了一种基于Transformer的革新性技术,名为Infini-Attention(无限注意力),它通过整合压缩记忆、局部遮蔽注意力等先进模块到传统的自注意力机制中,能够无缝地处理无限序列数据,同时确保内存和计算资源的有限使用。

Infini-Attention的主要特性:
1、压缩记忆
压缩记忆是Infini-Attention的核心组件之一,它允许大型模型以固定数量的参数来存储和回忆信息,从而实现对长篇文本的有效处理。这一机制与传统的注意力机制有所区别,其优势在于,随着输入序列长度的增加,压缩记忆并不会增加参数的数量,而是通过调整现有参数来吸收新信息,从而提升推理和计算的效率,并降低内存的使用。
在处理新的输入序列时,大型模型会在压缩记忆中结合新的key和value对。这个过程通过一个简单的关联绑定操作完成,将新的key和value对与记忆中已有的信息结合起来。这种更新机制确保了即使在处理极长的序列时,大模型也能以较低的内存需求完成处理并保持稳定。
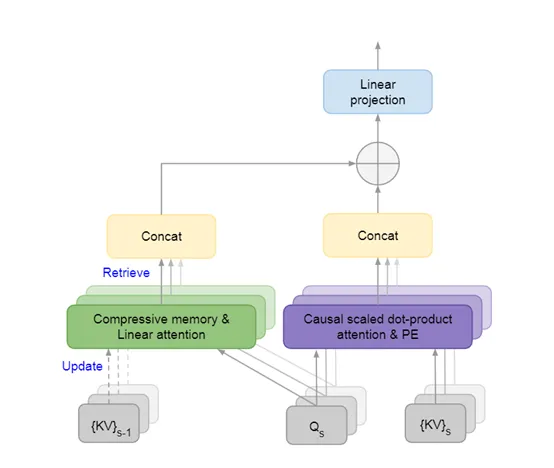
此外,为了提高大模型的检索效率,在处理每个新的输入序列时,Infini-Attention会利用当前的查询从压缩记忆中检索相关信息。这个过程主要通过线性注意力机制实现,将查询与记忆中的键进行匹配并返回相应的值。这种检索机制使得大模型在处理长篇文本时,能够有效利用之前序列中的信息。
2、记忆更新
记忆更新主要负责在处理新的输入序列时,更新压缩记忆模块中的key和value对,这样做旨在保持大模型的性能,同时减少内存占用和节约计算资源。
记忆更新借鉴了神经科学中的“Hebbian学习原则”。即当两个神经元同时被激活时,它们之间的连接会变得更强。这种机制支持学习和记忆的过程,使神经网络能够根据经验调整其内部连接。
在Infini-Attention中,新的输入信息通过注意力查询与现有的记忆键进行匹配,并将匹配结果直接更新到记忆中。每次更新过程中,记忆参数(通常是关联矩阵)会根据新的输入信息进行调整,通过计算新的key和value对与当前记忆状态的差值,然后将这个差值应用到关联矩阵上来实现。
策略方面,记忆更新模块采用的是“增量式更新策略”,每次只更新与当前输入相关的部分记忆。这种策略不仅提高了更新过程的效率,还减少了因大规模参数更新带来的不稳定性。
3、局部遮蔽注意力
Transformer的自注意力机制允许大模型在序列的任何位置查找信息,这在处理短文本时效果显著。然而,当输入序列变得非常长时,会导致计算成本呈指数级增长。
Infini-Attention的遮蔽机制主要用于限制大模型的注意力范围,使其只能关注当前处理的局部上下文,而不是无限制的全序列检索,从而节省计算资源。
对于每个输入序列,模型会创建一个与序列维度相同的遮蔽矩阵。遮蔽矩阵中的元素是一个二值矩阵,其中1表示允许注意力聚焦的标记,而0表示需要遮蔽的标记。
在计算自注意力分数时,大模型会将遮蔽矩阵与注意力分数矩阵相乘。这样,被遮蔽的标记对应的注意力分数会被设置为一个很小的值。通过遮蔽注意力分数,大模型可以计算加权和,即每个标记的上下文表示。这个加权和只包括未被遮蔽的标记,确保模型的输出集中在当前的局部上下文上,从而更好地捕捉和理解序列的连贯性。这对于生成长篇文本和处理复杂的语言结构至关重要。

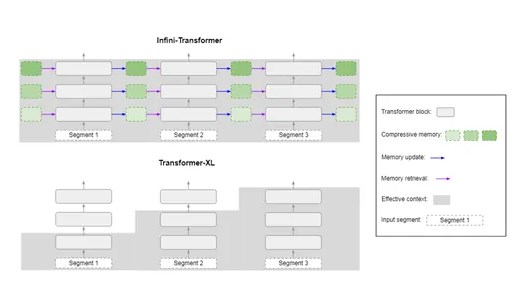
开发人员在长篇上下文语言建模、密钥检索任务和书籍摘要任务中对Infini-Attention进行了全面测试。结果显示,Infini-Attention模型在这些基准测试中的表现优于Transformer-XL和Memorizing Transformers等基础模型。尤其是在使用100K序列长度进行训练时,Infini-Attention的困惑度得分显著降低。
-

广告合作
-

QQ群号:707632017



















