
2024年2月16日凌晨,OpenAI在官网发布了首个文生视频模型——Sora,可以生成最长1分钟的高清视频,超过Gen-2、SVD-XT、Pika等主流产品,这一进展让文本生成视频技术迈入全新的时代。
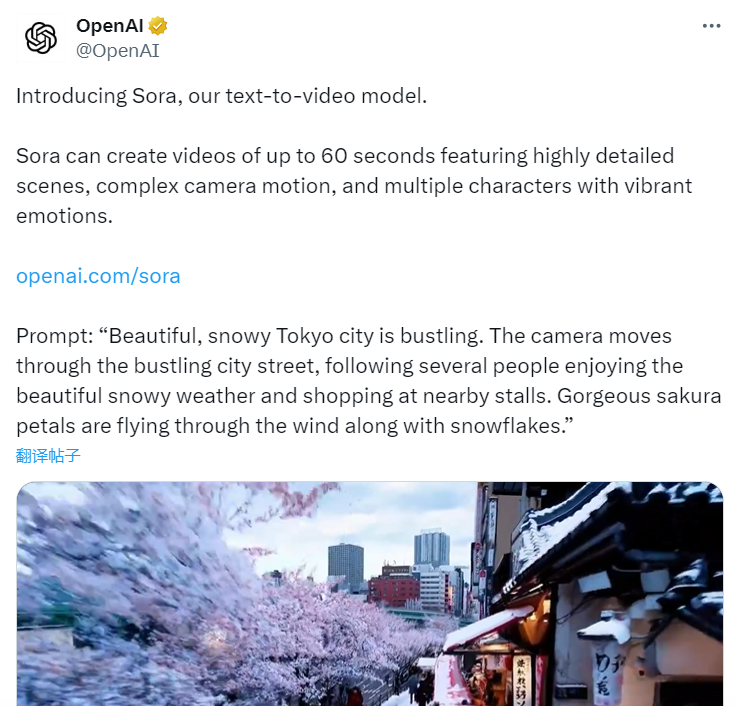
Sora是一种扩散模型,其生成视频的过程通常是从静态噪音的视频开始,然后通过多个步骤逐渐去除噪音,完成视频转换。类似于ChatGPT,Sora采用了Transformer架构,并应用了DALL-E 3中的重述技术,这种技术有助于为视觉训练数据生成准确描述性的字幕。因此,Sora在生成视频的过程中能够准确还原用户提供的文本提示的语义。另外,Sora 能够生成具有多个角色、特定类型的运动以及主题和背景的准确细节的复杂场景。该模型不仅了解用户在提示中要求的内容,还了解这些东西在物理世界中的存在方式。
除了可以根据文本生成视频外,Sora还具备根据图像生成视频的功能,并能够准确处理图像内容的动画效果。此外,Sora还能提取视频中的元素,对其进行扩展或填补缺失的帧,功能十分全面。
根据OpenAI在官网展示的Sora生成视频效果,能够看出其在视频质量、分辨率、文本语义还原、视频动作一致性、可控性、细节展现以及色彩表现等方面表现出色!生成的画面可以很好的展现场景中的光影关系、各个物体间的物理遮挡、碰撞关系,并且镜头丝滑可变。
OpenAI表示,目前Sora已经向“红队成员”开放,即那些能够评估风险并识别潜在问题的专家,还将向一些视觉艺术家、设计师和电影制作人开放,以获得有关如何推进模型以对创意专业人士最有帮助的反馈。
目前尚不清楚一旦Sora向公众开放,OpenAI是否会收取费用。然而,OpenAI已经推出了ChatGPT和其图像创建工具DALL-E的付费模型。2023年9月21日,OpenAI发布了文生图模型DALL·E3,加上现在的Sora以及之前的语音模型Whisper,ChatGPT已经具备了文本、图像、视频、音频4大多模态功能。
Sora 的出现让大家看到了人工智能的无限可能,促使视频行业朝着更高端、更创新的方向发展。
-

广告合作
-

QQ群号:4114653



















