
Kubernetes是一个流行的容器编排平台,Metrics API是其提供的一种API,用于收集和暴露关于节点和Pod的资源使用情况的指标。这些指标可以用于支持自动扩展、监控和调优等用例。通过部署Metrics API到Kubernetes集群中,Kubernetes API客户端可以查询这些指标,并在必要时使用Kubernetes的访问控制机制来管理权限。
Metrics API提供了一组基本的指标,包括CPU和内存使用情况等,这些指标可以帮助管理员更好地了解他们的集群的性能和健康状况。同时,这些指标也可以用于实现自动伸缩,根据实际负载情况动态调整集群中节点和Pod的数量。
HorizontalPodAutoscaler (HPA) 和 VerticalPodAutoscaler (VPA) 使用 metrics API 中的数据调整工作负载副本和资源,以满足客户需求。也可以通过 kubectl top 命令来查看资源指标。
注意:Metrics API 及其启用的指标管道仅提供最少的 CPU 和内存指标,以启用使用 HPA 和/或 VPA 的自动扩展。 如果想提供更完整的指标集,可以通过部署使用 Custom Metrics API 的第二个指标管道来作为简单的 Metrics API 的补充。
一、资源指标管道架构
下图说明了资源指标管道的架构:
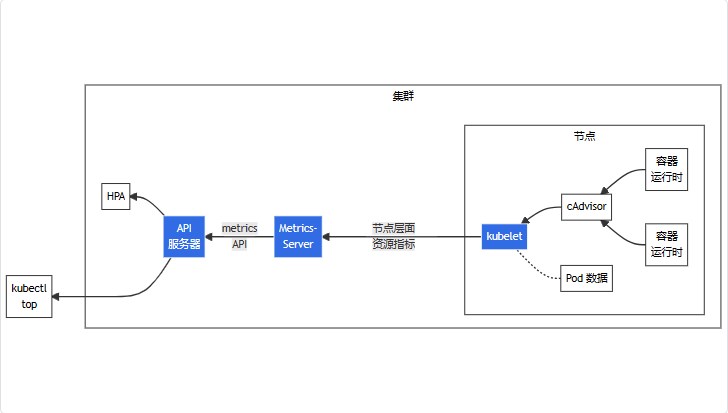
图中从右到左的架构组件包括以下内容:
1、cAdvisor: 用于收集、聚合和公开 Kubelet 中包含的容器指标的守护程序。
2、kubelet: 用于管理容器资源的节点代理。 可以使用 /metrics/resource 和 /stats kubelet API 端点访问资源指标。
3、节点层面资源指标: kubelet 提供的 API,用于发现和检索可通过 /metrics/resource 端点获得的每个节点的汇总统计信息。
4、metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。 API 服务器提供 Metrics API 以供 HPA、VPA 和 kubectl top 命令使用。Metrics Server 是 Metrics API 的参考实现。
5、Metrics API: Kubernetes API 支持访问用于工作负载自动缩放的 CPU 和内存。 要在集群中进行这项工作,需要一个提供 Metrics API 的 API 扩展服务器。
注意:cAdvisor 支持从 cgroups 读取指标,它适用于 Linux 上的典型容器运行时。 如果使用基于其他资源隔离机制的容器运行时,例如虚拟化,那么该容器运行时必须支持 CRI 容器指标 以便 kubelet 可以使用指标。
二、Metrics API
metrics-server 实现了 Metrics API。此 API 允许访问集群中节点和 Pod 的 CPU 和内存使用情况。 它的主要作用是将资源使用指标提供给 K8s 自动缩放器组件。
下面是一个 minikube 节点的 Metrics API 请求示例,通过 jq 管道处理以便于阅读:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes/minikube" | jq '.'
这是使用 curl 来执行的相同 API 调用:
curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/nodes/minikube
响应示例:
{
"kind": "NodeMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "minikube",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/minikube",
"creationTimestamp": "2022-01-27T18:48:43Z"
},
"timestamp": "2022-01-27T18:48:33Z",
"window": "30s",
"usage": {
"cpu": "487558164n",
"memory": "732212Ki"
}
}
下面是一个 kube-system 命名空间中的 kube-scheduler-minikube Pod 的 Metrics API 请求示例, 通过 jq 管道处理以便于阅读:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube" | jq '.'
这是使用 curl 来完成的相同 API 调用:
curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube
响应示例:
{
"kind": "PodMetrics",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"name": "kube-scheduler-minikube",
"namespace": "kube-system",
"selfLink": "/apis/metrics.k8s.io/v1beta1/namespaces/kube-system/pods/kube-scheduler-minikube",
"creationTimestamp": "2022-01-27T19:25:00Z"
},
"timestamp": "2022-01-27T19:24:31Z",
"window": "30s",
"containers": [
{
"name": "kube-scheduler",
"usage": {
"cpu": "9559630n",
"memory": "22244Ki"
}
}
]
}
Metrics API在Kubernetes的代码库中定义,具体路径是k8s.io/metrics。为了使用Metrics API,需要在Kubernetes集群上启用API聚合层,并注册一个名为metrics.k8s.io的APIService。
三、度量资源用量
1、CPU
CPU 报告为以 cpu 为单位测量的平均核心使用率。在 Kubernetes 中, 一个 cpu 相当于云提供商的 1 个 vCPU/Core,以及裸机 Intel 处理器上的 1 个超线程。
该值是通过对内核提供的累积 CPU 计数器(在 Linux 和 Windows 内核中)取一个速率得出的。 用于计算 CPU 的时间窗口显示在 Metrics API 的窗口字段下。
2、内存
内存报告为在收集度量标准的那一刻的工作集大小,以字节为单位。在理想情况下,“工作集”是在内存压力下无法释放的正在使用的内存量。 然而,工作集的计算因主机操作系统而异,并且通常大量使用启发式算法来产生估计。
Kubernetes 模型中,容器工作集是由容器运行时计算的与相关容器关联的匿名内存。 工作集指标通常还包括一些缓存(文件支持)内存,因为主机操作系统不能总是回收页面。
四、Metrics服务器
metrics-server 从 kubelet 中获取资源指标,并通过 Metrics API 在 Kubernetes API 服务器中公开它们,以供 HPA 和 VPA 使用。 还可以使用 kubectl top 命令查看这些指标。
metrics-server 使用 Kubernetes API 来跟踪集群中的节点和 Pod。metrics-server 服务器通过 HTTP 查询每个节点以获取指标。 metrics-server 还构建了 Pod 元数据的内部视图,并维护 Pod 健康状况的缓存。 缓存的 Pod 健康信息可通过 metrics-server 提供的扩展 API 获得。
例如,对于 HPA 查询,metrics-server 需要确定哪些 Pod 满足 Deployment 中的标签选择器。
metrics-server 调用 kubelet API 从每个节点收集指标。根据它使用的 metrics-server 版本:
- 版本 v0.6.0+ 中,使用指标资源端点 /metrics/resource
- 旧版本中使用 Summary API 端点 /stats/summary














