
在Kubernetes中,节点可以按照容量进行调度。默认情况下,Pod能够使用节点的全部可用容量。然而,这可能会导致问题,因为节点本身通常运行了许多驱动操作系统和Kubernetes的系统守护进程。如果未为这些系统守护进程留出资源,它们将与Pod竞争资源,从而导致节点资源短缺的问题。因此,为了确保系统的稳定运行,需要为这些系统守护进程预留一定的资源。
kubelet 公开了一个名为 ‘Node Allocatable’ 的特性,有助于为系统守护进程预留计算资源。 Kubernetes 推荐集群管理员按照每个节点上的工作负载密度配置 ‘Node Allocatable’。
一、准备
1、必须拥有一个 Kubernetes 的集群,同时必须配置 kubectl 命令行工具与集群通信。 建议在至少有两个不作为控制平面主机的节点的集群上运行本教程。 如果还没有集群,可以通过 Minikube 构建一个自己的集群,或者可以使用下面的 Kubernetes 练习环境之一:
- Killercoda
- 玩转 Kubernetes
2、Kubernetes 服务器版本必须不低于版本 1.8. 要获知版本信息,请输入 kubectl version.
3、 kubernetes 服务器版本必须至少是 1.17 版本,才能使用 kubelet 命令行选项 –reserved-cpus 设置显式预留 CPU 列表。
二、节点可分配资源
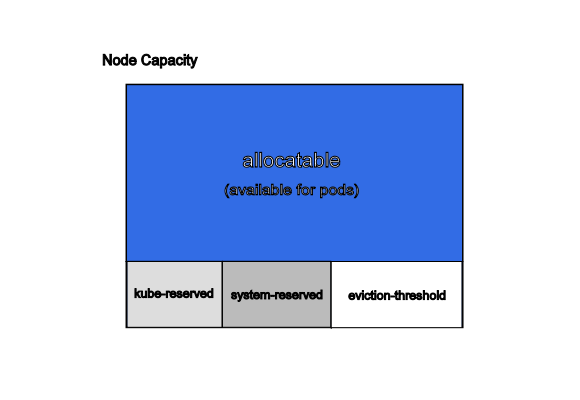
Kubernetes 节点上的 ‘Allocatable’ 被定义为 Pod 可用计算资源量。 调度器不会超额申请 ‘Allocatable’。 目前支持 ‘CPU’、’memory’ 和 ‘ephemeral-storage’ 这几个参数。
可分配的节点暴露为 API 中 v1.Node 对象的一部分,也是 CLI 中 kubectl describe node 的一部分。
在 kubelet 中,可以为两类系统守护进程预留资源。
1、启用 QoS 和 Pod 级别的 cgroups
为了恰当地在节点范围实施节点可分配约束,必须通过 –cgroups-per-qos 标志启用新的 cgroup 层次结构。这个标志是默认启用的。 启用后,kubelet 将在其管理的 cgroup 层次结构中创建所有终端用户的 Pod。
2、配置 cgroup 驱动
kubelet 支持在主机上使用 cgroup 驱动操作 cgroup 层次结构。 该驱动通过 –cgroup-driver 标志进行配置。
支持的参数值如下:
- cgroupfs 是默认的驱动,在主机上直接操作 cgroup 文件系统以对 cgroup 沙箱进行管理;
- systemd 是可选的驱动,使用 init 系统支持的资源的瞬时切片管理 cgroup 沙箱。
取决于相关容器运行时的配置,操作员可能需要选择一个特定的 cgroup 驱动来保证系统正常运行。 例如,如果操作员使用 containerd 运行时提供的 systemd cgroup 驱动时, 必须配置 kubelet 使用 systemd cgroup 驱动。
3、Kube 预留值
- Kubelet 标志:–kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
- Kubelet 标志:–kube-reserved-cgroup=
kube-reserved 用来给诸如 kubelet、容器运行时、节点问题监测器等 Kubernetes 系统守护进程记述其资源预留值。 该配置并非用来给以 Pod 形式运行的系统守护进程预留资源。kube-reserved 通常是节点上 Pod 密度 的函数。
除了 cpu、内存 和 ephemeral-storage 之外,pid 可用来指定为 Kubernetes 系统守护进程预留指定数量的进程 ID。要选择性地对 Kubernetes 系统守护进程上执行 kube-reserved 保护,需要把 kubelet 的 –kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。推荐将 Kubernetes 系统守护进程放置于顶级控制组之下(例如 systemd 机器上的 runtime.slice)。 理想情况下每个系统守护进程都应该在其自己的子控制组中运行。
注意:如果 –kube-reserved-cgroup 不存在,Kubelet 将 不会 创建它。 如果指定了一个无效的 cgroup,Kubelet 将会无法启动。就 systemd cgroup 驱动而言, 要为所定义的 cgroup 设置名称时要遵循特定的模式: 所设置的名字应该是为 –kube-reserved-cgroup 所给的参数值加上 .slice 后缀。
4、系统预留值
- Kubelet 标志:–system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
- Kubelet 标志:–system-reserved-cgroup=
system-reserved 用于为诸如 sshd、udev 等系统守护进程记述其资源预留值。 system-reserved 也应该为 kernel 预留 内存,因为目前 kernel 使用的内存并不记在 Kubernetes 的 Pod 上。 同时还推荐为用户登录会话预留资源(systemd 体系中的 user.slice)。
除了 cpu、内存 和 ephemeral-storage 之外,pid 可用来指定为 Kubernetes 系统守护进程预留指定数量的进程 ID要想为系统守护进程上可选地实施 system-reserved 约束,请指定 kubelet 的 –system-reserved-cgroup 标志值为 OS 系统守护进程的父级控制组推荐将 OS 系统守护进程放在一个顶级控制组之下(例如 systemd 机器上的 system.slice)。
注意:如果 –system-reserved-cgroup 不存在,kubelet 不会 创建它。 如果指定了无效的 cgroup,kubelet 将会失败。就 systemd cgroup 驱动而言, 在指定 cgroup 名字时要遵循特定的模式: 该名字应该是为 –system-reserved-cgroup 参数所设置的值加上 .slice 后缀。
5、显式预留的CPU列表
- Kubelet 标志: –reserved-cpus=0-3 KubeletConfiguration 标志:reservedSystemCPUs: 0-3
reserved-cpus 旨在为操作系统守护程序和 Kubernetes 系统守护程序预留一组明确指定编号的 CPU。 reserved-cpus 适用于不打算针对 cpuset 资源为操作系统守护程序和 Kubernetes 系统守护程序定义独立的顶级 cgroups 的系统。 如果 Kubelet 没有 指定参数 –system-reserved-cgroup 和 –kube-reserved-cgroup, 则 reserved-cpus 的设置将优先于 –kube-reserved 和 –system-reserved 选项。
此选项是专门为电信/NFV 用例设计的,在这些用例中不受控制的中断或计时器可能会影响其工作负载性能。 可以使用此选项为系统或 Kubernetes 守护程序以及中断或计时器显式定义 cpuset, 这样系统上的其余 CPU 可以专门用于工作负载,因不受控制的中断或计时器的影响得以降低。 要将系统守护程序、Kubernetes 守护程序和中断或计时器移动到此选项定义的显式 cpuset 上,应使用 Kubernetes 之外的其他机制。 例如:在 CentOS 系统中,可以使用 tuned 工具集来执行此操作。
6、驱逐阈值
- Kubelet 标志:–eviction-hard=[memory.available<500Mi]
节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod。 节点可以暂时离线直到内存已经回收为止。为了防止系统内存不足(或减少系统内存不足的可能性), kubelet 提供了资源不足管理。 驱逐操作只支持 memory 和 ephemeral-storage。 通过 –eviction-hard 标志预留一些内存后,当节点上的可用内存降至预留值以下时, kubelet 将尝试驱逐 Pod。 如果节点上不存在系统守护进程,Pod 将不能使用超过 capacity-eviction-hard 所指定的资源量。 因此,为驱逐而预留的资源对 Pod 是不可用的。
7、实施节点可分配约束
- Kubelet 标志:–enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
调度器将 ‘Allocatable’ 视为 Pod 可用的 capacity(资源容量)。
kubelet 默认对 Pod 执行 ‘Allocatable’ 约束。 无论何时,如果所有 Pod 的总用量超过了 ‘Allocatable’,驱逐 Pod 的措施将被执行。 可通过设置 kubelet –enforce-node-allocatable 标志值为 pods 控制这个措施。
可选地,通过在同一标志中同时指定 kube-reserved 和 system-reserved 值, 可以使 kubelet 强制实施 kube-reserved 和 system-reserved 约束。 请注意,要想执行 kube-reserved 或者 system-reserved 约束, 需要对应设置 –kube-reserved-cgroup 或者 –system-reserved-cgroup。
三、一般原则
系统守护进程一般会被按照类似 Guaranteed 的 Pod 一样对待。 系统守护进程可以在与其对应的控制组中出现突发资源用量,这一行为要作为 Kubernetes 部署的一部分进行管理。 例如,kubelet 应该有它自己的控制组并和容器运行时共享 kube-reserved 资源。 不过,如果执行了 kube-reserved 约束,则 kubelet 不可出现突发负载并用光节点的所有可用资源。
在执行 system-reserved 预留策略时请加倍小心,因为它可能导致节点上的关键系统服务出现 CPU 资源短缺、 因为内存不足而被终止或者无法在节点上创建进程。 建议只有当用户详尽地描述了他们的节点以得出精确的估计值, 并且对该组中进程因内存不足而被杀死时,有足够的信心将其恢复时, 才可以强制执行 system-reserved 策略。
- 作为起步,可以先针对 pods 上执行 ‘Allocatable’ 约束;
- 一旦用于追踪系统守护进程的监控和告警的机制到位,可尝试基于用量估计的方式执行 kube-reserved 策略;
- 随着时间推进,在绝对必要的时候可以执行 system-reserved 策略。
随着时间推进和越来越多特性被加入,kube 系统守护进程对资源的需求可能也会增加。 以后 Kubernetes 项目将尝试减少对节点系统守护进程的利用,但目前这件事的优先级并不是最高。 所以,将来的发布版本中 Allocatable 容量是有可能降低的。
四、示例
这是一个用于说明节点可分配(Node Allocatable)计算方式的示例:
- 节点拥有 32Gi memory、16 CPU 和 100Gi Storage 资源;
- –kube-reserved 被设置为 cpu=1,memory=2Gi,ephemeral-storage=1Gi;
- –system-reserved 被设置为 cpu=500m,memory=1Gi,ephemeral-storage=1Gi;
- –eviction-hard 被设置为 memory.available<500Mi,nodefs.available<10%。
在这个场景下,’Allocatable’ 将会是 14.5 CPUs、28.5Gi 内存以及 88Gi 本地存储。 调度器保证这个节点上的所有 Pod 的内存 requests 总量不超过 28.5Gi,存储不超过 ’88Gi’。 当 Pod 的内存使用总量超过 28.5Gi 或者磁盘使用总量超过 88Gi 时,kubelet 将会驱逐它们。 如果节点上的所有进程都尽可能多地使用 CPU,则 Pod 加起来不能使用超过 14.5 CPUs 的资源。
当没有执行 kube-reserved 和/或 system-reserved 策略且系统守护进程使用量超过其预留时, 如果节点内存用量高于 31.5Gi 或 storage 大于 90Gi,kubelet 将会驱逐 Pod。














