
使用拓扑分布约束(Topology Spread Constraints) 可以控制 Pod 在集群内故障域之间的分布, 例如区域(Region)、可用区(Zone)、节点和其他用户自定义拓扑域,有助于实现高可用并提升资源利用率。
可以将集群级约束设为默认值,或为个别工作负载配置拓扑分布约束。
一、动机
假设有一个最多包含二十个节点的集群,想要运行一个自动扩缩的工作负载,请问要使用多少个副本? 答案可能是最少 2 个 Pod,最多 15 个 Pod。 当只有 2 个 Pod 时,倾向于这 2 个 Pod 不要同时在同一个节点上运行: 所遭遇的风险是如果放在同一个节点上且单节点出现故障,可能会让工作负载下线。除了这个基本的用法之外,还有一些高级的使用案例,能够让工作负载受益于高可用性并提高集群利用率。
随着工作负载扩容,运行的 Pod 变多,将需要考虑另一个重要问题。 假设有 3 个节点,每个节点运行 5 个 Pod。这些节点有足够的容量能够运行许多副本; 但与这个工作负载互动的客户端分散在三个不同的数据中心(或基础设施可用区)。 现在可能不太关注单节点故障问题,但会注意到延迟高于自己的预期, 在不同的可用区之间发送网络流量会产生一些网络成本。
决定在正常运营时倾向于将类似数量的副本调度 到每个基础设施可用区,且想要该集群在遇到问题时能够自愈。Pod 拓扑分布约束使能够以声明的方式进行配置。
二、topologySpreadConstraints字段
Pod API 包括一个 spec.topologySpreadConstraints 字段,这个字段的用法如下所示:
—
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# 配置一个拓扑分布约束
topologySpreadConstraints:
– maxSkew: <integer>
minDomains: <integer> # 可选;自从 v1.25 开始成为 Beta
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # 可选;自从 v1.27 开始成为 Beta
nodeAffinityPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
nodeTaintsPolicy: [Honor|Ignore] # 可选;自从 v1.26 开始成为 Beta
### 其他 Pod 字段置于此处
1、分布约束定义
可以定义一个或多个 topologySpreadConstraints 条目以指导 kube-scheduler 如何将每个新来的 Pod 与跨集群的现有 Pod 相关联。这些字段包括:
(1)maxSkew 描述这些 Pod 可能被不均匀分布的程度。必须指定此字段且该数值必须大于零。 其语义将随着 whenUnsatisfiable 的值发生变化:
- 如果选择 whenUnsatisfiable: DoNotSchedule,则 maxSkew 定义目标拓扑中匹配 Pod 的数量与 全局最小值(符合条件的域中匹配的最小 Pod 数量,如果符合条件的域数量小于 MinDomains 则为零) 之间的最大允许差值。例如,如果有 3 个可用区,分别有 2、2 和 1 个匹配的 Pod,则 MaxSkew 设为 1, 且全局最小值为 1;
- 如果选择 whenUnsatisfiable: ScheduleAnyway,则该调度器会更为偏向能够降低偏差值的拓扑域。
(2)minDomains 表示符合条件的域的最小数量。此字段是可选的。域是拓扑的一个特定实例。 符合条件的域是其节点与节点选择器匹配的域。
注意:MinDomainsInPodTopologySpread 特性门控为 Pod 拓扑分布启用 minDomains。自 v1.28 起,MinDomainsInPodTopologySpread 特性门控默认被启用。 在早期的 Kubernetes 集群中,此特性门控可能被显式禁用或此字段可能不可用。
- 指定的 minDomains 值必须大于 0。可以结合 whenUnsatisfiable: DoNotSchedule 仅指定 minDomains;
- 当符合条件的、拓扑键匹配的域的数量小于 minDomains 时,拓扑分布将“全局最小值”(global minimum)设为 0, 然后进行 skew 计算。“全局最小值” 是一个符合条件的域中匹配 Pod 的最小数量, 如果符合条件的域的数量小于 minDomains,则全局最小值为零;
- 当符合条件的拓扑键匹配域的个数等于或大于 minDomains 时,该值对调度没有影响;
- 如果未指定 minDomains,则约束行为类似于 minDomains 等于 1。
(3)topologyKey 是节点标签的键。如果节点使用此键标记并且具有相同的标签值, 则将这些节点视为处于同一拓扑域中。我们将拓扑域中(即键值对)的每个实例称为一个域。 调度器将尝试在每个拓扑域中放置数量均衡的 Pod。 另外,我们将符合条件的域定义为其节点满足 nodeAffinityPolicy 和 nodeTaintsPolicy 要求的域。
(4)whenUnsatisfiable 指示如果 Pod 不满足分布约束时如何处理:
- DoNotSchedule(默认)告诉调度器不要调度;
- ScheduleAnyway 告诉调度器仍然继续调度,只是根据如何能将偏差最小化来对节点进行排序。
(5)labelSelector 用于查找匹配的 Pod。匹配此标签的 Pod 将被统计,以确定相应拓扑域中 Pod 的数量。
(6)matchLabelKeys 是一个 Pod 标签键的列表,用于选择需要计算分布方式的 Pod 集合, 这些键用于从 Pod 标签中查找值,这些键值标签与 labelSelector 进行逻辑与运算,以选择一组已有的 Pod, 通过这些 Pod 计算新来 Pod 的分布方式。matchLabelKeys 和 labelSelector 中禁止存在相同的键, 未设置 labelSelector 时无法设置 matchLabelKeys。Pod 标签中不存在的键将被忽略; null 或空列表意味着仅与 labelSelector 匹配。
借助 matchLabelKeys,无需在变更 Pod 修订版本时更新 pod.spec。 控制器或 Operator 只需要将不同修订版的标签键设为不同的值, 调度器将根据 matchLabelKeys 自动确定取值。例如,如果正在配置一个 Deployment, 则可以使用由 Deployment 控制器自动添加的、以 pod-template-hash 为键的标签来区分同一个 Deployment 的不同修订版。
topologySpreadConstraints: - maxSkew: 1 topologyKey: kubernetes.io/hostname whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: foo matchLabelKeys: - pod-template-hash
注意:matchLabelKeys 字段是 1.27 中默认启用的一个 Beta 级别字段。 可以通过禁用 MatchLabelKeysInPodTopologySpread 特性门控来禁用此字段。
(7)nodeAffinityPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理 Pod 的 nodeAffinity/nodeSelector。 选项为:
- Honor:只有与 nodeAffinity/nodeSelector 匹配的节点才会包括到计算中;
- Ignore:nodeAffinity/nodeSelector 被忽略。所有节点均包括到计算中。
如果此值为 nil,此行为等同于 Honor 策略。
注意:nodeAffinityPolicy 是 1.26 中默认启用的一个 Beta 级别字段,可以通过禁用 NodeInclusionPolicyInPodTopologySpread 特性门控来禁用此字段。
(8)nodeTaintsPolicy 表示我们在计算 Pod 拓扑分布偏差时将如何处理节点污点。选项为:
- Honor:包括不带污点的节点以及污点被新 Pod 所容忍的节点;
- Ignore:节点污点被忽略,包括所有节点。
如果此值为 null,此行为等同于 Ignore 策略。
注意:nodeTaintsPolicy 是一个 Beta 级别字段,在 1.26 版本默认启用。 可以通过禁用 NodeInclusionPolicyInPodTopologySpread 特性门控来禁用此字段。
当 Pod 定义了不止一个 topologySpreadConstraint,这些约束之间是逻辑与的关系。 kube-scheduler 会为新的 Pod 寻找一个能够满足所有约束的节点。
2、节点标签
拓扑分布约束依赖于节点标签来标识每个节点所在的拓扑域。 例如,某节点可能具有标签:
region: us-east-1 zone: us-east-1a
为了简便,此示例未使用众所周知的标签键 topology.kubernetes.io/zone 和 topology.kubernetes.io/region。 但是,建议使用那些已注册的标签键,而不是此处使用的私有(不合格)标签键 region 和 zone。你无法对不同上下文之间的私有标签键的含义做出可靠的假设。
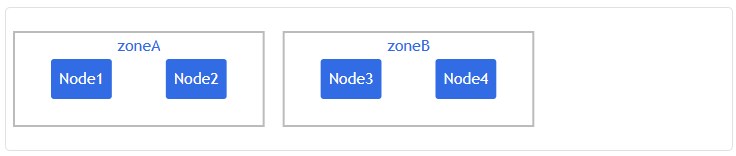
假设有一个 4 节点的集群且带有以下标签:
NAME STATUS ROLES AGE VERSION LABELS
node1 Ready <none> 4m26s v1.16.0 node=node1,zone=zoneA
node2 Ready <none> 3m58s v1.16.0 node=node2,zone=zoneA
node3 Ready <none> 3m17s v1.16.0 node=node3,zone=zoneB
node4 Ready <none> 2m43s v1.16.0 node=node4,zone=zoneB那么,从逻辑上看集群如下:
三、一致性
应该为一个组中的所有 Pod 设置相同的 Pod 拓扑分布约束。通常,如果正使用一个工作负载控制器,例如 Deployment,则 Pod 模板会帮解决这个问题。 如果混合不同的分布约束,则 Kubernetes 会遵循该字段的 API 定义; 但是,该行为可能更令人困惑,并且故障排除也没那么简单。
需要一种机制来确保拓扑域(例如云提供商区域)中的所有节点具有一致的标签。 为了避免需要手动为节点打标签,大多数集群会自动填充知名的标签, 例如 kubernetes.io/hostname。检查集群是否支持此功能。
四、拓扑分布约束示例
1、一个拓扑分布约束
假设拥有一个 4 节点集群,其中标记为 foo: bar 的 3 个 Pod 分别位于 node1、node2 和 node3 中:
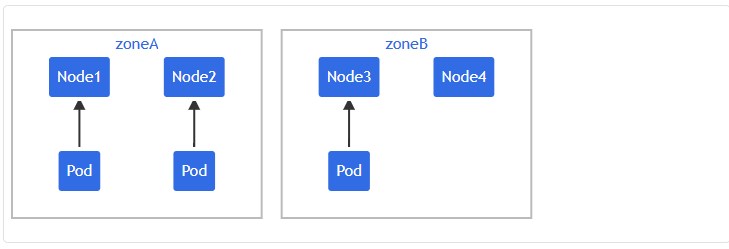
如果希望新来的 Pod 均匀分布在现有的可用区域,则可以按如下设置其清单:
kind: Pod apiVersion: v1 metadata: name: mypod labels: foo: bar spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar containers: - name: pause image: registry.k8s.io/pause:3.1
从此清单看,topologyKey: zone 意味着均匀分布将只应用于存在标签键值对为 zone: <any value> 的节点 (没有 zone 标签的节点将被跳过)。如果调度器找不到一种方式来满足此约束, 则 whenUnsatisfiable: DoNotSchedule 字段告诉该调度器将新来的 Pod 保持在 pending 状态。
如果该调度器将这个新来的 Pod 放到可用区 A,则 Pod 的分布将成为 [3, 1]。 这意味着实际偏差是 2(计算公式为 3 – 1),这违反了 maxSkew: 1 的约定。 为了满足这个示例的约束和上下文,新来的 Pod 只能放到可用区 B 中的一个节点上:
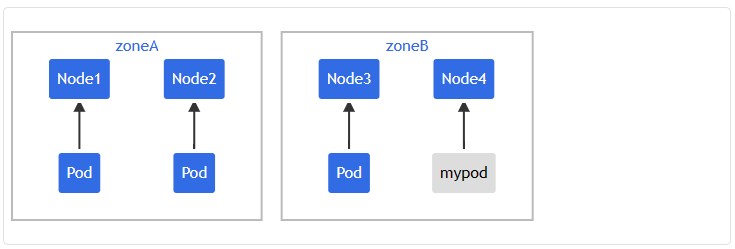
或者:
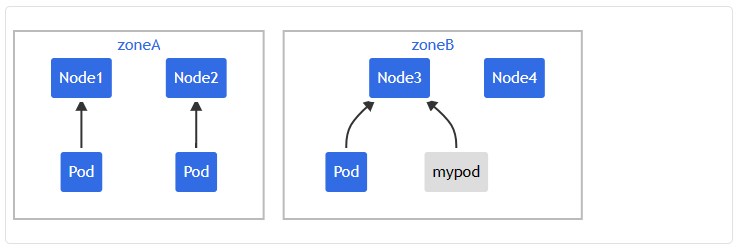
可以调整 Pod 规约以满足各种要求:
- 将 maxSkew 更改为更大的值,例如 2,这样新来的 Pod 也可以放在可用区 A 中;
- 将 topologyKey 更改为 node,以便将 Pod 均匀分布在节点上而不是可用区中。 在上面的例子中,如果 maxSkew 保持为 1,则新来的 Pod 只能放到 node4 节点上;
- 将 whenUnsatisfiable: DoNotSchedule 更改为 whenUnsatisfiable: ScheduleAnyway, 以确保新来的 Pod 始终可以被调度(假设满足其他的调度 API)。但是,最好将其放置在匹配 Pod 数量较少的拓扑域中。 请注意,这一优先判定会与其他内部调度优先级(如资源使用率等)排序准则一起进行标准化。
2、多个拓扑分布约束
下面的例子建立在前面例子的基础上。假设拥有一个 4 节点集群, 其中 3 个标记为 foo: bar 的 Pod 分别位于 node1、node2 和 node3 上:

可以组合使用 2 个拓扑分布约束来控制 Pod 在节点和可用区两个维度上的分布:
kind: Pod apiVersion: v1 metadata: name: mypod labels: foo: bar spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar - maxSkew: 1 topologyKey: node whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar containers: - name: pause image: registry.k8s.io/pause:3.1
在这种情况下,为了匹配第一个约束,新的 Pod 只能放置在可用区 B 中; 而在第二个约束中,新来的 Pod 只能调度到节点 node4 上。 该调度器仅考虑满足所有已定义约束的选项,因此唯一可行的选择是放置在节点 node4 上。
3、有冲突的拓扑分布约束
多个约束可能导致冲突,假设有一个跨 2 个可用区的 3 节点集群:
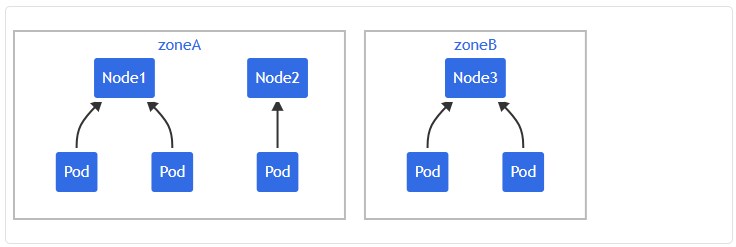
如果将 two-constraints.yaml (来自上一个示例的清单)应用到这个集群,将看到 Pod mypod 保持在 Pending 状态。 出现这种情况的原因为:为了满足第一个约束,Pod mypod 只能放置在可用区 B 中; 而在第二个约束中,Pod mypod 只能调度到节点 node2 上。 两个约束的交集将返回一个空集,且调度器无法放置该 Pod。
为了应对这种情形,可以提高 maxSkew 的值或修改其中一个约束才能使用 whenUnsatisfiable: ScheduleAnyway。 根据实际情形,例如若在故障排查时发现某个漏洞修复工作毫无进展,还可能决定手动删除一个现有的 Pod。
与节点亲和性和节点选择算符的相互作用:如果 Pod 定义了 spec.nodeSelector 或 spec.affinity.nodeAffinity, 调度器将在偏差计算中跳过不匹配的节点。
4、带节点亲和性的拓扑分布约束
假设有一个跨可用区 A 到 C 的 5 节点集群:
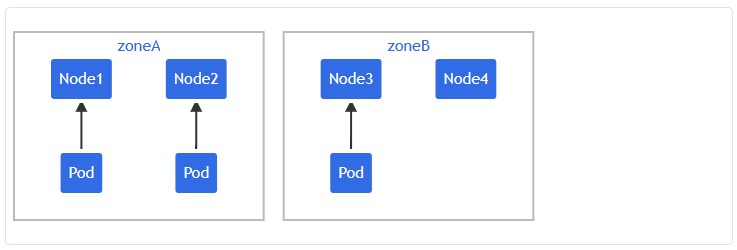

而且知道可用区 C 必须被排除在外。在这种情况下,可以按如下方式编写清单, 以便将 Pod mypod 放置在可用区 B 上,而不是可用区 C 上。 同样,Kubernetes 也会一样处理 spec.nodeSelector。
kind: Pod apiVersion: v1 metadata: name: mypod labels: foo: bar spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: zone operator: NotIn values: - zoneC containers: - name: pause image: registry.k8s.io/pause:3.1
五、隐式约定
这里有一些值得注意的隐式约定:
1、只有与新来的 Pod 具有相同命名空间的 Pod 才能作为匹配候选者。
2、调度器会忽略没有任何 topologySpreadConstraints[*].topologyKey 的节点。这意味着:
- 位于这些节点上的 Pod 不影响 maxSkew 计算,在上面的例子中,假设节点 node1 没有标签 “zone”, 则 2 个 Pod 将被忽略,因此新来的 Pod 将被调度到可用区 A 中;
- 新的 Pod 没有机会被调度到这类节点上。在上面的例子中, 假设节点 node5 带有 拼写错误的 标签 zone-typo: zoneC(且没有设置 zone 标签)。 节点 node5 接入集群之后,该节点将被忽略且针对该工作负载的 Pod 不会被调度到那里。
3、如果新 Pod 的 topologySpreadConstraints[*].labelSelector 与自身的标签不匹配,将会发生什么。 在上面的例子中,如果移除新 Pod 的标签,则 Pod 仍然可以放置到可用区 B 中的节点上,因为这些约束仍然满足。 然而,在放置之后,集群的不平衡程度保持不变。可用区 A 仍然有 2 个 Pod 带有标签 foo: bar, 而可用区 B 有 1 个 Pod 带有标签 foo: bar。如果这不是所期望的, 更新工作负载的 topologySpreadConstraints[*].labelSelector 以匹配 Pod 模板中的标签。
六、集群级别的默认约束
为集群设置默认的拓扑分布约束也是可能的。默认拓扑分布约束在且仅在以下条件满足时才会被应用到 Pod 上:
- Pod 没有在其 .spec.topologySpreadConstraints 中定义任何约束;
- Pod 隶属于某个 Service、ReplicaSet、StatefulSet 或 ReplicationController。
默认约束可以设置为调度方案中 PodTopologySpread 插件参数的一部分。约束的设置采用如前所述的 API, 只是 labelSelector 必须为空。 选择算符是根据 Pod 所属的 Service、ReplicaSet、StatefulSet 或 ReplicationController 来设置的。
配置的示例可能看起来像下面这个样子:
apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler pluginConfig: - name: PodTopologySpread args: defaultConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: ScheduleAnyway defaultingType: List
1、内置默认约束
如果没有为 Pod 拓扑分布配置任何集群级别的默认约束, kube-scheduler 的行为就像指定了以下默认拓扑约束一样:
defaultConstraints: - maxSkew: 3 topologyKey: "kubernetes.io/hostname" whenUnsatisfiable: ScheduleAnyway - maxSkew: 5 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway
此外,原来用于提供等同行为的 SelectorSpread 插件默认被禁用。
注意:
- 对于分布约束中所指定的拓扑键而言,PodTopologySpread 插件不会为不包含这些拓扑键的节点评分。 这可能导致在使用默认拓扑约束时,其行为与原来的 SelectorSpread 插件的默认行为不同;
- 如果节点不会 同时 设置 kubernetes.io/hostname 和 topology.kubernetes.io/zone 标签, 应该定义自己的约束而不是使用 Kubernetes 的默认约束。
如果不想为集群使用默认的 Pod 分布约束,可以通过设置 defaultingType 参数为 List, 并将 PodTopologySpread 插件配置中的 defaultConstraints 参数置空来禁用默认 Pod 分布约束:
apiVersion: kubescheduler.config.k8s.io/v1beta3 kind: KubeSchedulerConfiguration profiles: - schedulerName: default-scheduler pluginConfig: - name: PodTopologySpread args: defaultConstraints: [] defaultingType: List
七、比较podAffinity和podAntiAffinity
在 Kubernetes 中, Pod 间亲和性和反亲和性控制 Pod 彼此的调度方式(更密集或更分散)。
1、podAffinity:吸引 Pod;可以尝试将任意数量的 Pod 集中到符合条件的拓扑域中。
2、podAntiAffinity:驱逐 Pod。如果将此设为requiredDuringSchedulingIgnoredDuringExecution 模式, 则只有单个 Pod 可以调度到单个:扑域;如果选择 preferredDuringSchedulingIgnoredDuringExecution, 则将丢失强制执行此约束的能力。
要实现更细粒度的控制,可以设置拓扑分布约束来将 Pod 分布到不同的拓扑域下,从而实现高可用性或节省成本。 这也有助于工作负载的滚动更新和平稳地扩展副本规模。
八、已知局限性
当 Pod 被移除时,无法保证约束仍被满足。例如,缩减某 Deployment 的规模时,Pod 的分布可能不再均衡,这时可以使用 Descheduler 来重新实现 Pod 分布的均衡。
该调度器不会预先知道集群拥有的所有可用区和其他拓扑域。 拓扑域由集群中存在的节点确定。在自动扩缩的集群中,如果一个节点池(或节点组)的节点数量缩减为零, 而用户正期望其扩容时,可能会导致调度出现问题。 因为在这种情况下,调度器不会考虑这些拓扑域,直至这些拓扑域中至少包含有一个节点。
也可以通过使用感知 Pod 拓扑分布约束并感知整个拓扑域集的集群自动扩缩工具来解决此问题。














