
一、简介
资源配额是 Kubernetes 中的一种机制,用于限制用户或团队在共享具有固定节点数目的集群时的资源使用量。它的主要作用包括限制命名空间下所创建对象的数量和计算资源的总量。
资源配额通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。这种限制可以在命名空间级别上应用,包括计算资源和限制命名空间内的对象数量。例如,它可以限制吊舱 (Pod)、服务 (Service)、机密信息 (Secret)、持久卷断言 (Persistent Volume Claim) (PVC)和配置映射 (ConfigMap)这些对象的 CPU 和内存的使用。
二、工作方式
资源配额的工作方式如下:
1、不同的团队可以在不同的命名空间下工作,可以通过 RBAC 强制执行。
2、集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
3、当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会跟踪集群的资源使用情况, 以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
4、如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
5、如果命名空间下的计算资源 (如 cpu 和 memory)的配额被启用, 则用户必须为这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 或者可使用 LimitRanger 准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
注意:
- ResourceQuota 对象的名称必须是合法的 DNS 子域名;
- 对于 cpu 和 memory 资源:ResourceQuota 强制该命名空间中的每个(新)Pod 为该资源设置限制。 如果在命名空间中为 cpu 和 memory 实施资源配额, 或其他客户端必须为提交的每个新 Pod 指定该资源的 requests 或 limits。 否则,控制平面可能会拒绝接纳该 Pod;
- 对于其他资源:ResourceQuota 可以工作,并且会忽略命名空间中的 Pod,而无需为该资源设置限制或请求。 这意味着,如果资源配额限制了此命名空间的临时存储,则可以创建没有限制/请求临时存储的新 Pod。 可以使用限制范围自动设置对这些资源的默认请求。
下面是使用命名空间和配额构建策略的示例:
1、在具有 32 GiB 内存和 16 核 CPU 资源的集群中,允许 A 团队使用 20 GiB 内存 和 10 核的 CPU 资源, 允许 B 团队使用 10 GiB 内存和 4 核的 CPU 资源,并且预留 2 GiB 内存和 2 核的 CPU 资源供将来分配。
2、限制 “testing” 命名空间使用 1 核 CPU 资源和 1GiB 内存。允许 “production” 命名空间使用任意数量。
在集群容量小于各命名空间配额总和的情况下,可能存在资源竞争。资源竞争时,Kubernetes 系统会遵循先到先得的原则。不管是资源竞争还是配额的修改,都不会影响已经创建的资源使用对象。
三、启用资源配额
资源配额的支持在很多 Kubernetes 版本中是默认启用的。 当 API 服务器 的命令行标志 –enable-admission-plugins= 中包含 ResourceQuota 时, 资源配额会被启用。当命名空间中存在一个 ResourceQuota 对象时,对于该命名空间而言,资源配额就是开启的。
四、计算资源配额
用户可以对给定命名空间下的可被请求的计算资源总量进行限制。配额机制所支持的资源类型:

1、扩展资源的资源配额
除上述资源外,在 Kubernetes 1.10 版本中,还添加了对扩展资源的支持。由于扩展资源不可超量分配,因此没有必要在配额中为同一扩展资源同时指定 requests 和 limits。 对于扩展资源而言,目前仅允许使用前缀为 requests. 的配额项。
以 GPU 拓展资源为例,如果资源名称为 nvidia.com/gpu,并且要将命名空间中请求的 GPU 资源总数限制为 4,则可以如下定义配额:
requests.nvidia.com/gpu: 4
五、存储资源配额
用户可以对给定命名空间下的存储资源总量进行限制。还可以根据相关的存储类(Storage Class)来限制存储资源的消耗。
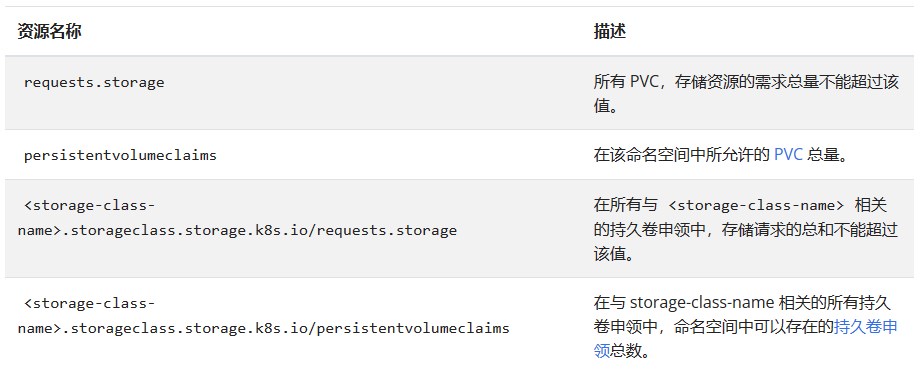
例如,如果一个操作人员针对 gold 存储类型与 bronze 存储类型设置配额, 操作人员可以定义如下配额:
- gold.storageclass.storage.k8s.io/requests.storage: 500Gi
- bronze.storageclass.storage.k8s.io/requests.storage: 100Gi
在 Kubernetes 1.8 版本中,本地临时存储的配额支持已经是 Alpha 功能:
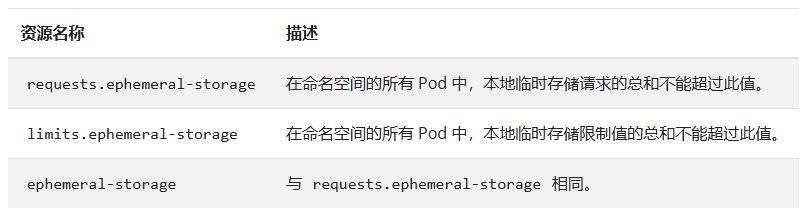
注意:如果所使用的是 CRI 容器运行时,容器日志会被计入临时存储配额, 可能会导致存储配额耗尽的 Pods 被意外地驱逐出节点。
六、对象数量配额
可以使用以下语法对所有标准的、命名空间域的资源类型进行配额设置:
- count/<resource>.<group>:用于非核心(core)组的资源
- count/<resource>:用于核心组的资源
这是用户可能希望利用对象计数配额来管理的一组资源示例。
- count/persistentvolumeclaims
- count/services
- count/secrets
- count/configmaps
- count/replicationcontrollers
- count/deployments.apps
- count/replicasets.apps
- count/statefulsets.apps
- count/jobs.batch
- count/cronjobs.batch
相同语法也可用于自定义资源。 例如,要对 example.com API 组中的自定义资源 widgets 设置配额,请使用 count/widgets.example.com。
当使用 count/* 资源配额时,如果对象存在于服务器存储中,则会根据配额管理资源。 这些类型的配额有助于防止存储资源耗尽。例如,用户可能想根据服务器的存储能力来对服务器中 Secret 的数量进行配额限制。 集群中存在过多的 Secret 实际上会导致服务器和控制器无法启动。 用户可以选择对 Job 进行配额管理,以防止配置不当的 CronJob 在某命名空间中创建太多 Job 而导致集群拒绝服务。
对有限的一组资源上实施一般性的对象数量配额也是可能的。支持以下类型:

例如,pods 配额统计某个命名空间中所创建的、非终止状态的 Pod 个数并确保其不超过某上限值。 用户可能希望在某命名空间中设置 pods 配额,以避免有用户创建很多小的 Pod, 从而耗尽集群所能提供的 Pod IP 地址。
七、配额作用域
每个配额都有一组相关的 scope(作用域),配额只会对作用域内的资源生效。 配额机制仅统计所列举的作用域的交集中的资源用量。当一个作用域被添加到配额中后,它会对作用域相关的资源数量作限制, 如配额中指定了允许(作用域)集合之外的资源,会导致验证错误。
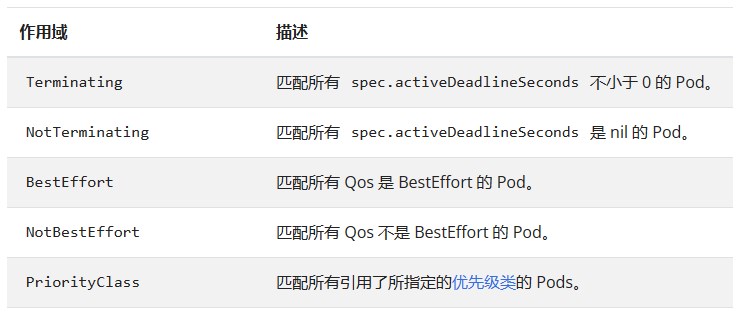
BestEffort 作用域限制配额跟踪以下资源:
- pods
Terminating、NotTerminating、NotBestEffort 和 PriorityClass 这些作用域限制配额跟踪以下资源:
- pods
- cpu
- memory
- requests.cpu
- requests.memory
- limits.cpu
- limits.memory
需要注意的是,不可以在同一个配额对象中同时设置 Terminating 和 NotTerminating 作用域,也不可以在同一个配额中同时设置 BestEffort 和 NotBestEffort 作用域。
scopeSelector 支持在 operator 字段中使用以下值:
- In
- NotIn
- Exists
- DoesNotExist
定义 scopeSelector 时,如果使用以下值之一作为 scopeName 的值,则对应的 operator 只能是 Exists。
- Terminating
- NotTerminating
- BestEffort
- NotBestEffort
如果 operator 是 In 或 NotIn 之一,则 values 字段必须至少包含一个值。 例如:
scopeSelector: matchExpressions: - scopeName: PriorityClass operator: In values: - middle
如果 operator 为 Exists 或 DoesNotExist,则不可以设置 values 字段。
1、基于优先级类(PriorityClass)来设置资源配额
Pod 可以创建为特定的优先级。 通过使用配额规约中的 scopeSelector 字段,用户可以根据 Pod 的优先级控制其系统资源消耗。仅当配额规范中的 scopeSelector 字段选择到某 Pod 时,配额机制才会匹配和计量 Pod 的资源消耗。如果配额对象通过 scopeSelector 字段设置其作用域为优先级类, 则配额对象只能跟踪以下资源:
- pods
- cpu
- memory
- ephemeral-storage
- limits.cpu
- limits.memory
- limits.ephemeral-storage
- requests.cpu
- requests.memory
- requests.ephemeral-storage
本示例创建一个配额对象,并将其与具有特定优先级的 Pod 进行匹配。 该示例的工作方式如下:
- 集群中的 Pod 可取三个优先级类之一,即 “low”、”medium”、”high”;
- 为每个优先级创建一个配额对象。
将以下 YAML 保存到文件 quota.yml 中。
apiVersion: v1 kind: List items: - apiVersion: v1 kind: ResourceQuota metadata: name: pods-high spec: hard: cpu: "1000" memory: 200Gi pods: "10" scopeSelector: matchExpressions: - operator: In scopeName: PriorityClass values: ["high"] - apiVersion: v1 kind: ResourceQuota metadata: name: pods-medium spec: hard: cpu: "10" memory: 20Gi pods: "10" scopeSelector: matchExpressions: - operator: In scopeName: PriorityClass values: ["medium"] - apiVersion: v1 kind: ResourceQuota metadata: name: pods-low spec: hard: cpu: "5" memory: 10Gi pods: "10" scopeSelector: matchExpressions: - operator: In scopeName: PriorityClass values: ["low"]
使用 kubectl create 命令运行以下操作。
kubectl create -f ./quota.yml
resourcequota/pods-high created resourcequota/pods-medium created resourcequota/pods-low created
使用 kubectl describe quota 操作验证配额的 Used 值为 0。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10创建优先级为 “high” 的 Pod。 将以下 YAML 保存到文件 high-priority-pod.yml 中。
apiVersion: v1 kind: Pod metadata: name: high-priority spec: containers: - name: high-priority image: ubuntu command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10;done"] resources: requests: memory: "10Gi" cpu: "500m" limits: memory: "10Gi" cpu: "500m" priorityClassName: high
使用 kubectl create 运行以下操作。
kubectl create -f ./high-priority-pod.yml
确认 “high” 优先级配额 pods-high 的 “Used” 统计信息已更改,并且其他两个配额未更改。
kubectl describe quota
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 102、跨名字空间的 Pod 亲和性配额
集群运维人员可以使用 CrossNamespacePodAffinity 配额作用域来限制哪个名字空间中可以存在包含跨名字空间亲和性规则的 Pod。 更为具体一点,此作用域用来配置哪些 Pod 可以在其 Pod 亲和性规则中设置 namespaces 或 namespaceSelector 字段。
禁止用户使用跨名字空间的亲和性规则可能是一种被需要的能力, 因为带有反亲和性约束的 Pod 可能会阻止所有其他名字空间的 Pod 被调度到某失效域中。
使用此作用域操作符可以避免某些名字空间(例如下面例子中的 foo-ns)运行特别的 Pod, 这类 Pod 使用跨名字空间的 Pod 亲和性约束,在该名字空间中创建了作用域为 CrossNamespacePodAffinity 的、硬性约束为 0 的资源配额对象。
apiVersion: v1 kind: ResourceQuota metadata: name: disable-cross-namespace-affinity namespace: foo-ns spec: hard: pods: "0" scopeSelector: matchExpressions: - scopeName: CrossNamespacePodAffinity operator: Exists
如果集群运维人员希望默认禁止使用 namespaces 和 namespaceSelector, 而仅仅允许在特定名字空间中这样做,他们可以将 CrossNamespacePodAffinity 作为一个被约束的资源。方法是为 kube-apiserver 设置标志 –admission-control-config-file,使之指向如下的配置文件:
apiVersion: apiserver.config.k8s.io/v1 kind: AdmissionConfiguration plugins: - name: "ResourceQuota" configuration: apiVersion: apiserver.config.k8s.io/v1 kind: ResourceQuotaConfiguration limitedResources: - resource: pods matchScopes: - scopeName: CrossNamespacePodAffinity operator: Exists
基于上面的配置,只有名字空间中包含作用域为 CrossNamespacePodAffinity 且硬性约束大于或等于使用 namespaces 和 namespaceSelector 字段的 Pod 个数时,才可以在该名字空间中继续创建在其 Pod 亲和性规则中设置 namespaces 或 namespaceSelector 的新 Pod。
八、请求与限制的比较
分配计算资源时,每个容器可以为 CPU 或内存指定请求和约束。 配额可以针对二者之一进行设置。如果配额中指定了 requests.cpu 或 requests.memory 的值,则它要求每个容器都显式给出对这些资源的请求。 同理,如果配额中指定了 limits.cpu 或 limits.memory 的值,那么它要求每个容器都显式设定对应资源的限制。
九、查看和设置配额
Kubectl 支持创建、更新和查看配额:
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources spec: hard: requests.cpu: "1" requests.memory: 1Gi limits.cpu: "2" limits.memory: 2Gi requests.nvidia.com/gpu: 4 EOF
kubectl create -f ./compute-resources.yaml --namespace=myspace
cat <<EOF > object-counts.yaml apiVersion: v1 kind: ResourceQuota metadata: name: object-counts spec: hard: configmaps: "10" persistentvolumeclaims: "4" pods: "4" replicationcontrollers: "20" secrets: "10" services: "10" services.loadbalancers: "2" EOF
kubectl create -f ./object-counts.yaml --namespace=myspace
kubectl get quota --namespace=myspace
NAME AGE compute-resources 30s object-counts 32s
kubectl describe quota compute-resources --namespace=myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4kubectl describe quota object-counts --namespace=myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2kubectl 还使用语法 count/<resource>.<group> 支持所有标准的、命名空间域的资源的对象计数配额:
kubectl create namespace myspace
kubectl create quota test --hard=count/deployments.apps=2,count/replicasets.apps=4,count/pods=3,count/secrets=4 --namespace=myspace
kubectl create deployment nginx --image=nginx --namespace=myspace --replicas=2
kubectl describe quota --namespace=myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4十、配额和集群容量
ResourceQuota 与集群资源总量是完全独立的。它们通过绝对的单位来配置。 所以,为集群添加节点时,资源配额不会自动赋予每个命名空间消耗更多资源的能力。
有时可能需要资源配额支持更复杂的策略,比如:
- 在几个团队中按比例划分总的集群资源;
- 允许每个租户根据需要增加资源使用量,但要有足够的限制以防止资源意外耗尽
- 探测某个命名空间的需求,添加物理节点并扩大资源配额值。
这些策略可以通过将资源配额作为一个组成模块、手动编写一个控制器来监控资源使用情况, 并结合其他信号调整命名空间上的硬性资源配额来实现。
注意:资源配额对集群资源总体进行划分,但它对节点没有限制:来自不同命名空间的 Pod 可能在同一节点上运行。
十一、默认情况下资源消耗
有时候可能希望当且仅当某名字空间中存在匹配的配额对象时,才可以创建特定优先级 (例如 “cluster-services”)的 Pod。
通过这种机制,操作人员能够限制某些高优先级类仅出现在有限数量的命名空间中, 而并非每个命名空间默认情况下都能够使用这些优先级类。要实现此目的,应设置 kube-apiserver 的标志 –admission-control-config-file 指向如下配置文件:
apiVersion: apiserver.config.k8s.io/v1 kind: AdmissionConfiguration plugins: - name: "ResourceQuota" configuration: apiVersion: apiserver.config.k8s.io/v1 kind: ResourceQuotaConfiguration limitedResources: - resource: pods matchScopes: - scopeName: PriorityClass operator: In values: ["cluster-services"]
现在在 kube-system 名字空间中创建一个资源配额对象:
apiVersion: v1 kind: ResourceQuota metadata: name: pods-cluster-services spec: scopeSelector: matchExpressions: - operator : In scopeName: PriorityClass values: ["cluster-services"]
kubectl apply -f https://k8s.io/examples/policy/priority-class-resourcequota.yaml -n kube-system
resourcequota/pods-cluster-services created
在这里,当以下条件满足时可以创建 Pod:
- Pod 未设置 priorityClassName;
- Pod 的 priorityClassName 设置值不是 cluster-services;
- Pod 的 priorityClassName 设置值为 cluster-services,它将被创建于 kube-system 名字空间中,并且它已经通过了资源配额检查。
如果 Pod 的 priorityClassName 设置为 cluster-services,但要被创建到 kube-system 之外的别的名字空间,则 Pod 创建请求也被拒绝。














